
What's Inside
Topic 1
Cache-Aside vs Write-Through
Cache-Aside: The Industry Default
Cache-aside (also called lazy loading or look-aside) is the most widely used caching pattern. The application owns the caching logic: it checks the cache before querying the database, and populates the cache on a miss. The cache is a passive store — it does not know about the database and does not load data on its own.
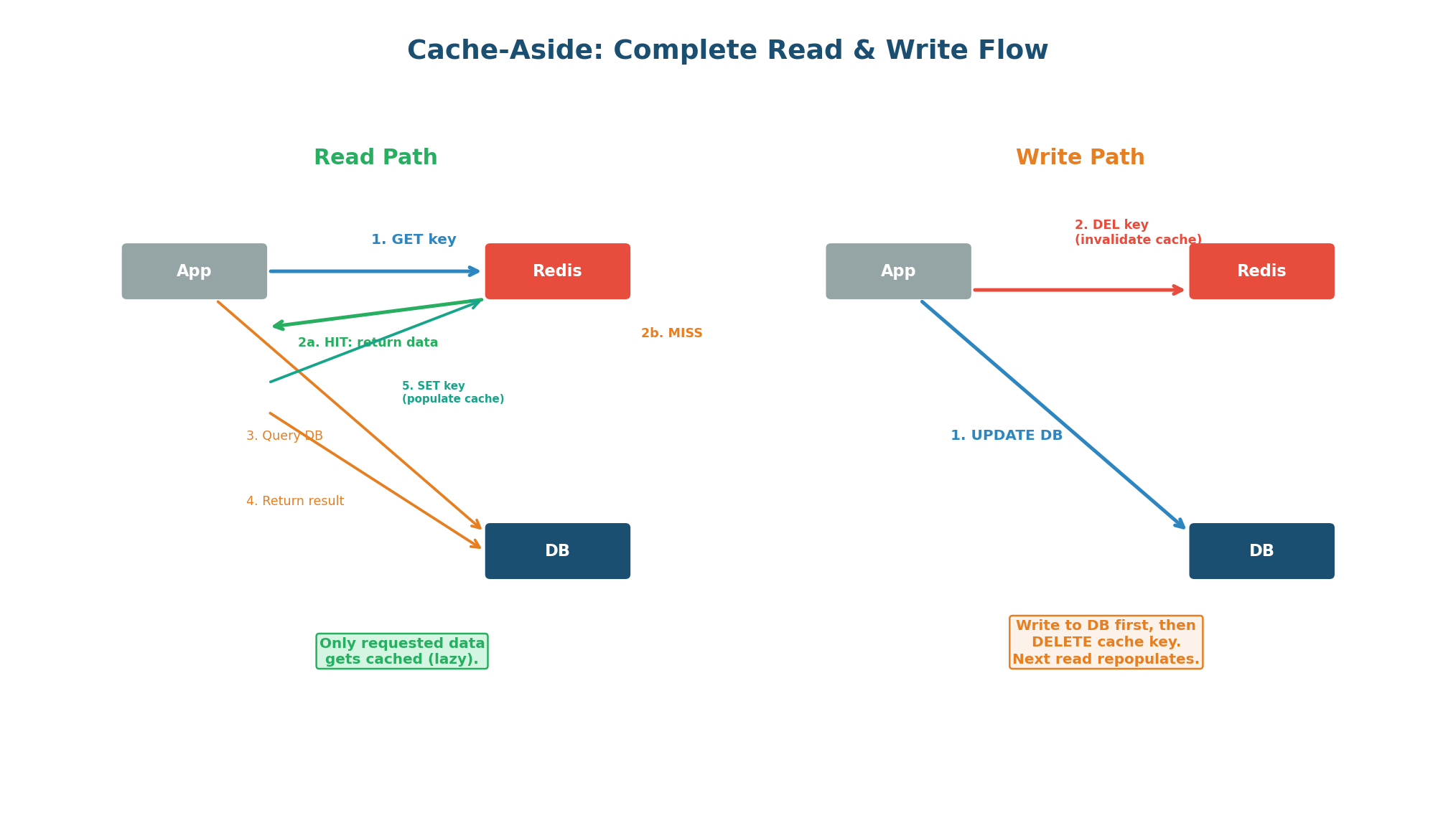
Read Path (Step by Step)
- Application receives a read request for
user:42. - Application calls Redis:
GET user:42. - Cache HIT: Redis returns the data. Application sends it to the client. Done in <1ms.
- Cache MISS: Redis returns null. Application queries PostgreSQL:
SELECT * FROM users WHERE id = 42. - Application stores the result in Redis:
SET user:42 <data> EX 3600(1-hour TTL). - Application returns the data to the client. Next request for
user:42will hit cache.
Write Path: Delete, Do Not Update
When data changes (UPDATE, DELETE), the application writes to the database first, then deletes the cache key. It does NOT update the cache with the new value. Why? Because deleting is simpler and safer: if the database write succeeds but the cache update fails, the cache has stale data. With delete, the worst case is a cache miss on the next read, which repopulates from the authoritative database.
Imagine two concurrent writes: Thread A updates price to $99, Thread B updates price to $129.
With cache UPDATE: Thread A writes DB ($99), Thread B writes DB ($129), Thread A updates cache ($99), Thread B updates cache ($129). Cache shows $129, DB shows $129 — correct. But if Thread B's cache update happens before Thread A's: cache shows $99, DB shows $129 — WRONG.
With cache DELETE: Both threads delete the key. Next read gets $129 from DB. Always correct.
Write-Through: Always-Fresh Cache
In write-through caching, every write operation updates both the cache and the database synchronously. The client does not receive confirmation until both writes succeed. This guarantees the cache is always consistent with the database — there is never a stale read. The trade-off is higher write latency (two writes per operation) and the fact that all data is cached, even data that may never be read.
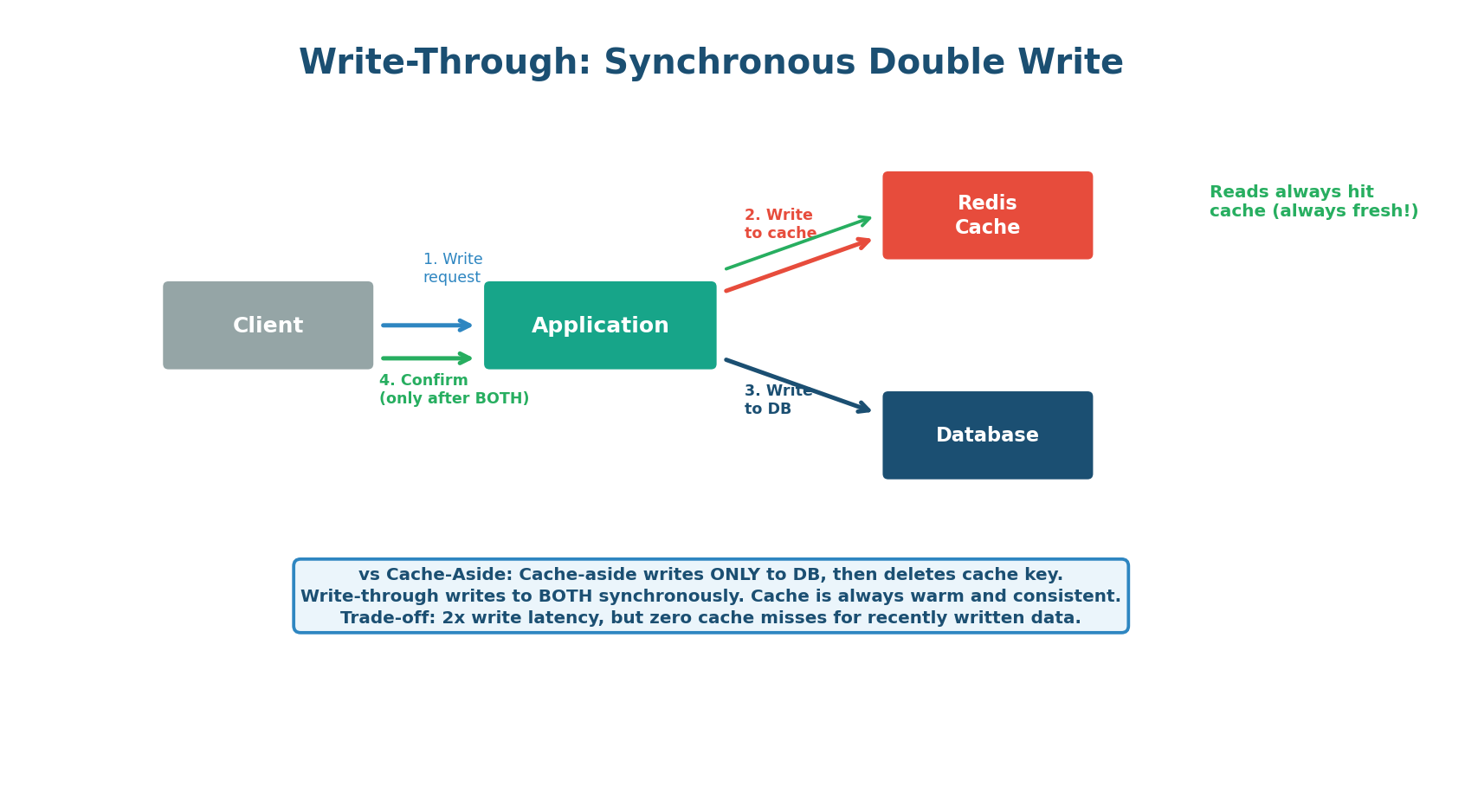
When to use Write-Through over Cache-Aside:
- Data must never be stale (user permissions, feature flags, pricing)
- Write frequency is low
- You need the cache to always be warm
Stick with Cache-Aside when:
- You have a read-heavy workload (90%+ reads)
- You cannot afford the write latency overhead
- You only want to cache data that is actually requested (memory efficiency)

| Pattern | Read | Write | Consistency | Latency | Best For |
|---|---|---|---|---|---|
| Cache-Aside | App → Cache → DB | App → DB → DEL cache | Eventual (TTL) | Low reads, normal writes | 90% of systems (default) |
| Write-Through | App → Cache | App → Cache + DB | Strong | Normal reads, 2x writes | Consistency-critical data |
| Write-Behind | App → Cache | App → Cache (async DB) | Weak | Fast writes | Metrics, view counts |
| Read-Through | App → Cache (auto-load) | Varies | Depends | Low reads | Simplified app code |
| Refresh-Ahead | App → Cache (pre-warmed) | N/A | Strong | Zero misses | Predictable access patterns |
Explicitly name the pattern and state your read:write ratio reasoning. "I'll use cache-aside because this is a read-heavy workload — 95% reads, 5% writes — and I want to only cache what's actually requested." This specificity separates strong candidates from average ones.
Topic 2
Cache Invalidation Deep Dive

Five Invalidation Strategies Ranked
1. TTL Expiry (Simplest)
Every cache key has a Time-To-Live. After the TTL expires, the key is automatically deleted. The stale window is exactly the TTL. Set shorter TTLs for frequently changing data (inventory: 10s) and longer TTLs for stable data (product descriptions: 24h). No code needed beyond setting the TTL at write time.
2. Delete on Write (Most Common)
When the application writes to the database, it also deletes the corresponding cache key. The stale window is essentially zero. This is the standard approach for cache-aside and should be your default for any data that changes via your application's write path.
3. Event-Driven Invalidation (Best for Microservices)
When data changes in the database, a change event is published to a message queue (Kafka). A cache invalidation consumer listens for these events and deletes the corresponding cache keys. This decouples the writing service from the caching logic.
When the Profile Service updates a user's job title in PostgreSQL, it publishes a profile.updated event to Kafka. The Feed Service, Search Service, and Messaging Service each have consumers that invalidate their respective cache entries for that user. No service needs to know about the others' caches.
4. Version Stamping (No Explicit Deletion)
Append a version number to the cache key: user:42:v7. When the user's data changes, increment the version to v8. The application always reads from the latest version key. The old key user:42:v7 expires naturally via its TTL. This approach never requires explicit cache deletion — the old data simply becomes unreachable.
5. Stale-While-Revalidate (Best User Experience)
The cache serves the stale value immediately (zero latency for the user) while triggering a background refresh. The user gets the old value instantly, and the next request gets the fresh value. HTTP's Cache-Control: stale-while-revalidate header implements this at the CDN/browser level.
Cache Stampede Solutions
A cache stampede (thundering herd) occurs when a popular cache key expires and hundreds or thousands of concurrent requests all experience a cache miss simultaneously, potentially overwhelming the database.
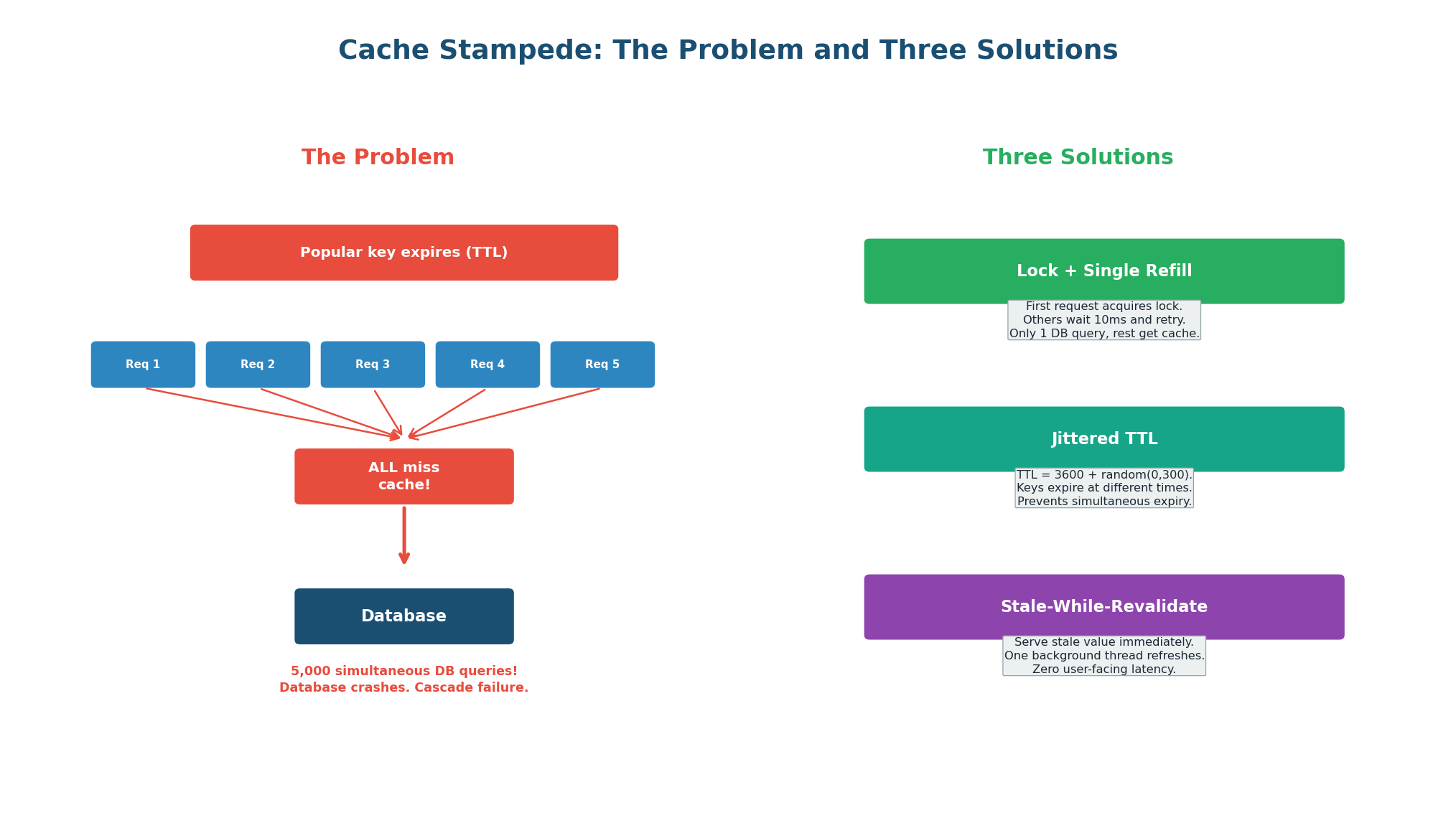
Solution 1: Lock + Single Refill
First request acquires a Redis SETNX lock, queries DB, repopulates cache. Other requests wait 10–50ms and retry from cache. Result: 1 database query instead of 5,000. This is the most effective solution for high-concurrency keys.
Solution 2: Jittered TTL
TTL = 3600 + random(0, 300). Keys expire at slightly different times, preventing simultaneous mass-expiry events. Very low complexity — just add a random offset when setting the TTL. Best for systems with many similar keys (product pages, user profiles).
Solution 3: Stale-While-Revalidate
Track a "soft TTL" (data is stale) and "hard TTL" (data is deleted). Return stale data + trigger background refresh. The key never truly expires, so there is no stampede. Best user experience — the user always gets a fast response.
| Solution | Complexity | Effectiveness | Use When |
|---|---|---|---|
| Lock + Single Refill | Medium | Excellent | High-concurrency keys (product pages, feeds) |
| Jittered TTL | Low | Good for mass expiry | Many keys expiring at similar times |
| Stale-While-Revalidate | High | Best UX | Latency-critical user-facing data |
| Pre-warming | Low | Prevents cold start | Predictable traffic patterns (scheduled) |
Proactively mention stampede prevention when discussing caching — it shows production awareness. Say: "I'd add jitter to TTLs to prevent mass simultaneous expiry, and use a lock-based refill pattern for the most popular keys."
Topic 3
The Hot Key Problem
When One Key Gets All the Traffic
The hot key problem occurs when a single cache key receives disproportionately high traffic, overwhelming the Redis node that stores it. Even though Redis can handle 100,000+ ops/sec, a single hot key during a flash sale or viral event can generate 1,000,000+ reads/sec to one key.
Cache Stampede: occurs when a key expires and many requests miss simultaneously. The key is absent.
Hot Key: occurs when a key exists but is read so frequently it overwhelms the Redis node. The key is always present — the node is overloaded by volume of reads.
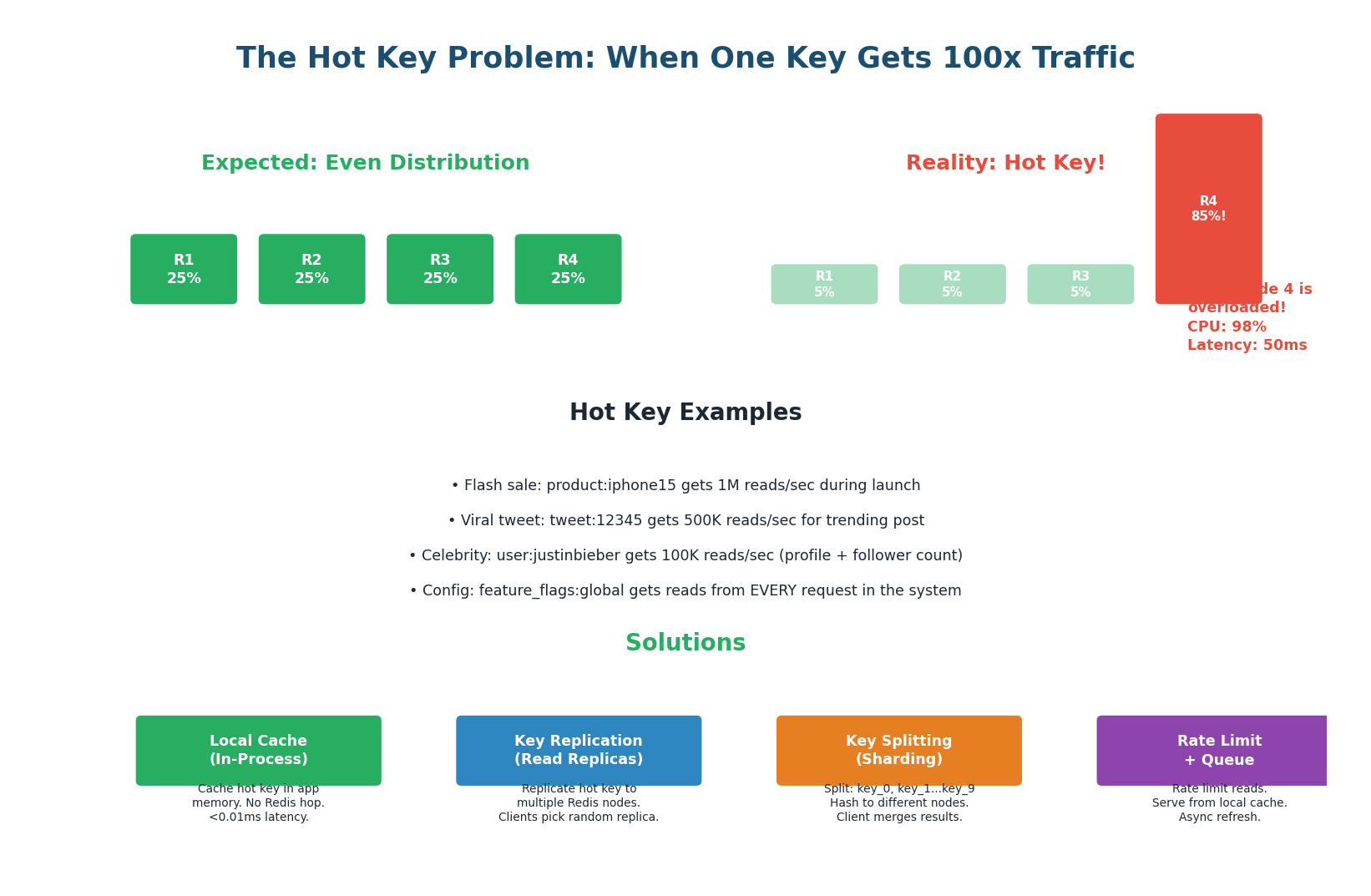
- Flash Sale (Amazon/Flipkart):
product:iphone15gets 1 million reads/sec during a sale launch. - Viral Content (Twitter/Instagram):
tweet:12345for a viral post gets 500K reads/sec. - Global Config (Feature Flags):
feature_flags:globalis read by EVERY request in the system. With 100K RPS, this single key gets 100K reads/sec on one Redis node.
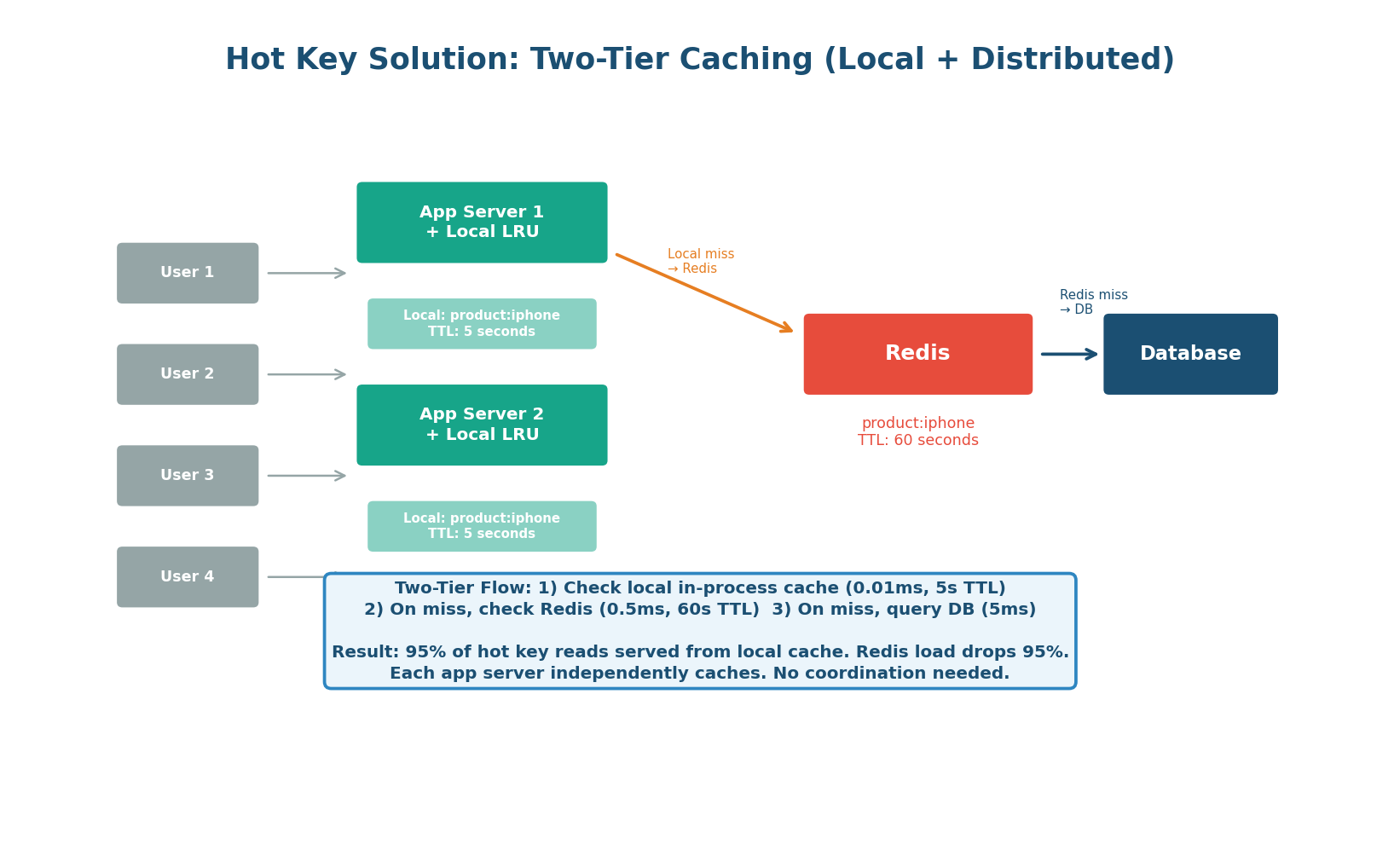
Solution 1: Two-Tier Caching (Local + Distributed) — The Default
Add a small in-process LRU cache (local cache) within each application server, in front of Redis. Hot keys are cached locally with a very short TTL (5–10 seconds). With 10 app servers, Redis receives at most 2 reads/second for that key (10 servers × 1 miss per 5 seconds) instead of 1,000,000 reads/sec. That is a 500,000x reduction in Redis load.
Solution 2: Key Replication (Read Replicas)
Replicate the hot key to multiple Redis nodes: product:iphone15:r0 through product:iphone15:r4, all containing the same data. Application hashes a random suffix to choose a replica. With 5 replicas, each handles 1/5th of the traffic.
Solution 3: Key Splitting (Sharding a Single Key)
Split the hot key's data across multiple keys: product:iphone15:0 through product:iphone15:9. Each sub-key maps to a different Redis node via consistent hashing. The application randomly picks a sub-key for each read. Trade-off: writes must update all 10 sub-keys.
| Solution | Read Reduction | Write Impact | Staleness | Complexity | Best For |
|---|---|---|---|---|---|
| Local LRU Cache | ~99.9% | None | 5–10 seconds | Low | Default solution for all hot keys |
| Key Replication | 1/N per replica | N writes per update | Milliseconds | Medium | Known hot keys with fast updates |
| Key Splitting | 1/N per shard | N writes per update | Milliseconds | High | Extreme traffic (1M+ RPS) |
| Rate Limiting | Controlled | None | None | Low | Protect Redis from abuse |
When a key exceeds 10K reads/sec, it is automatically promoted to a 'hot key list' that gets cached locally on every app server with a 5-second TTL. The local cache is an in-process Python dict with LRU eviction (max 1,000 keys). This happens transparently without any manual configuration.
Proactively raise the hot key problem for any system with caching. Say: "One concern I'd flag is hot keys — during a flash sale, a single product key could get millions of reads per second on one Redis node. I'd add a local in-process cache with a 5-second TTL on each app server to absorb 99% of that traffic." Raising problems before the interviewer asks shows senior-level thinking.
Topic 4
CDN Architecture Deep Dive
Inside a CDN Edge: What Happens at Each Step
A CDN (Content Delivery Network) is a globally distributed network of edge servers (Points of Presence or PoPs) that cache content close to users. A CDN PoP handles TLS termination, security filtering, caching, compression, and intelligent routing — all in the 5–10ms between receiving a request and returning a response.
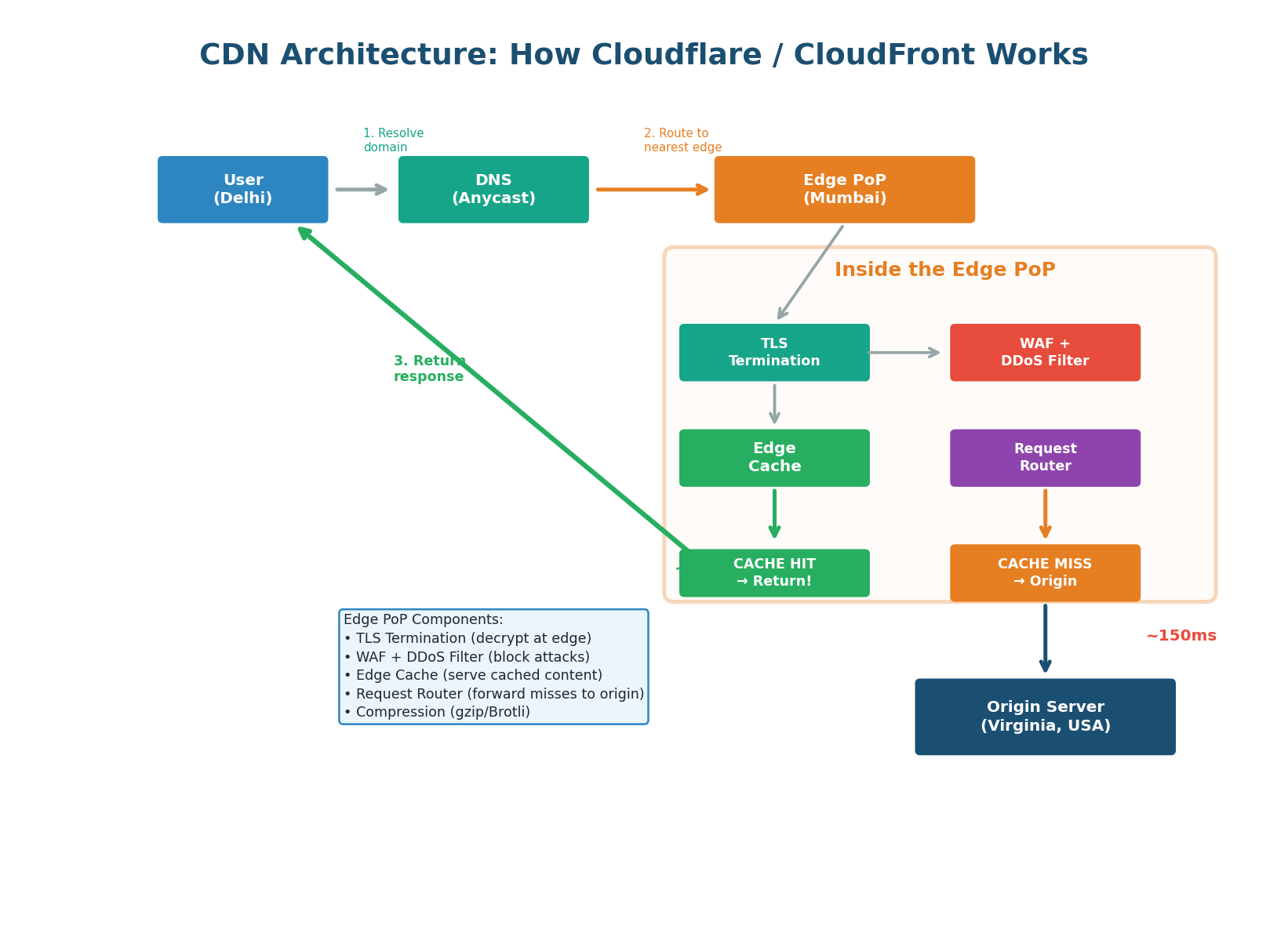
Step-by-Step CDN Request Flow:
- DNS Resolution (Anycast): CDN uses Anycast routing so the DNS query returns the IP of the nearest PoP (e.g., Mumbai PoP at 10ms vs. Virginia origin at 150ms).
- TLS Termination at Edge: The PoP decrypts the TLS connection at the edge, eliminating the TLS round-trip to the origin. Saves 40–80ms for users far from origin.
- WAF and DDoS Filtering: Web Application Firewall blocks SQL injection, XSS, and known attack patterns. DDoS mitigation absorbs attack traffic at the edge. Cloudflare's edge can absorb multi-terabit attacks.
- Edge Cache Lookup: PoP checks local cache. Cache HIT: response returned immediately (~5ms total). Cache MISS: request forwarded to origin. Edge hit rate is typically 60–80% for well-configured sites.
- Origin Fetch (on miss): Edge forwards to origin server. Origin response is stored in edge cache (per Cache-Control headers) and returned to user.
- Response Optimization: PoP compresses (gzip/Brotli), converts images (WebP), minifies HTML/CSS/JS, and adds security headers (HSTS, CSP).
CDN Cache Invalidation
CDN caches are distributed across hundreds of PoPs worldwide. CDN providers offer a Purge API that invalidates content across all PoPs simultaneously, but propagation takes 5–30 seconds.

Best Practice: Versioned URLs + TTL
Use fingerprinted URLs for all static assets (e.g., style.a3f2b1.css). When the file changes, the filename changes and CDN naturally fetches the new version. Set max-age=31536000 (1 year) for static assets. For dynamic content, use s-maxage=60 to s-maxage=300 with stale-while-revalidate.
| Content Type | CDN Strategy | TTL | Invalidation |
|---|---|---|---|
| JS / CSS / Fonts | Fingerprinted URL | 1 year | New deploy = new filename |
| Images | Fingerprinted or versioned | 1 year | New upload = new URL |
| Product page HTML | TTL + stale-while-revalidate | 5 min + 1hr stale | Auto-refresh on access |
| API response (public) | Cache-Control: s-maxage | 1–10 min | TTL expiry or Purge API |
| API response (private) | Cache-Control: private, no-store | 0 | Never cached at CDN |
| User-specific data | Never cache at CDN | N/A | Cache-Control: private |
Cloudflare operates 300+ PoPs in 100+ countries. Each PoP runs: Anycast BGP routing, TLS termination (with 0-RTT session resumption), a Lua-based WAF, a tiered cache (RAM → SSD → origin), Argo Smart Routing, and Workers (serverless functions at the edge). A typical Cloudflare-served request completes in under 10ms globally.
Putting It All Together
Production Caching Architecture
In a production system, caching is a pipeline of progressively more expensive lookups. Each layer catches a fraction of requests, dramatically reducing load on layers below. Only ~2% of all read requests ever reach the database.
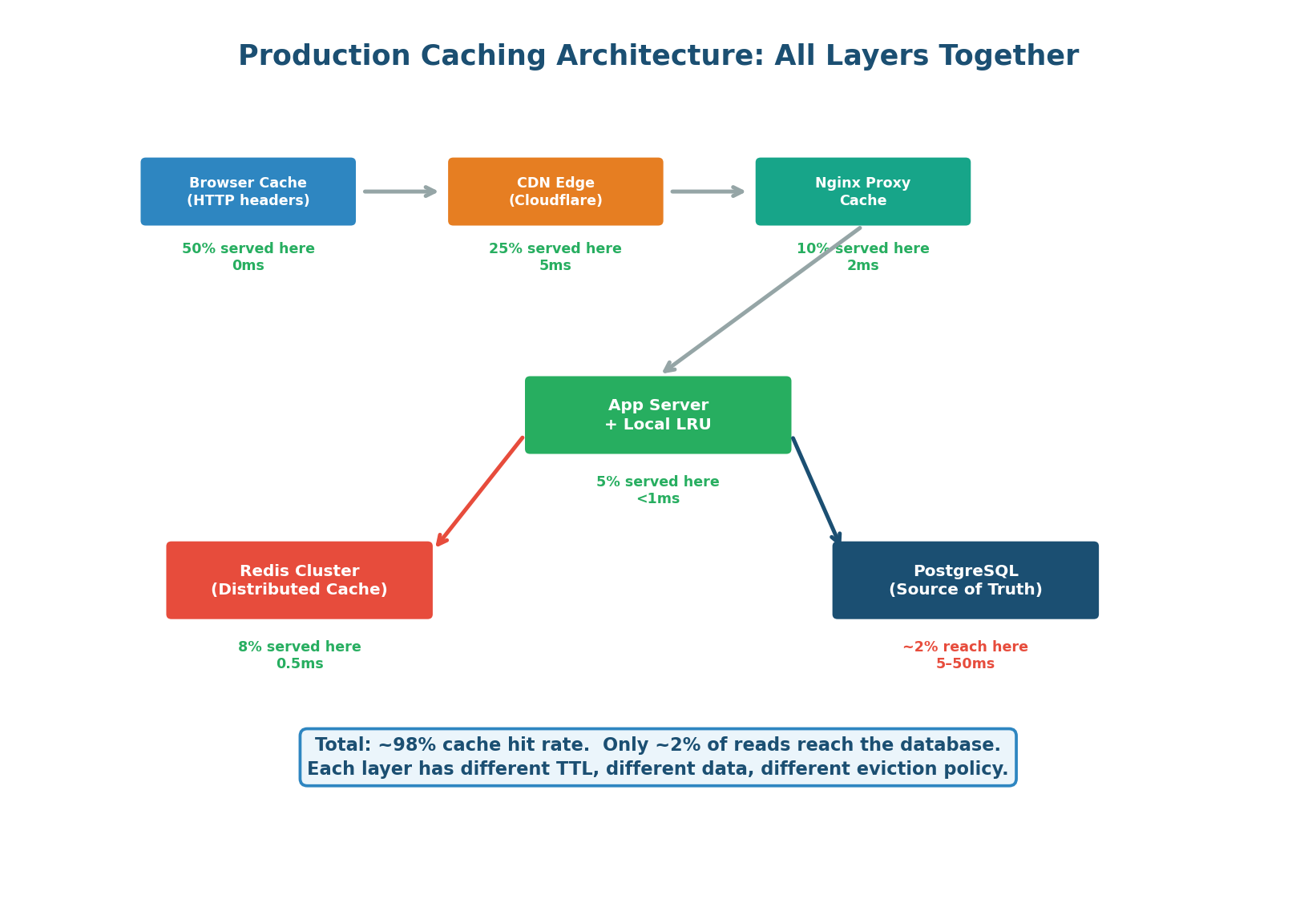
| Layer | Technology | Hit Rate | Latency | TTL Strategy | Eviction |
|---|---|---|---|---|---|
| Browser | HTTP Cache-Control | ~50% | 0ms | max-age per content type | N/A |
| CDN Edge | Cloudflare / CloudFront | ~25% | 1–5ms | s-maxage + stale-while-revalidate | TTL + purge API |
| Reverse Proxy | Nginx proxy_cache | ~10% | 1–2ms | proxy_cache_valid | LRU (keys_zone) |
| Local Cache | In-process LRU (dict) | ~5% | <0.01ms | 5–10 seconds (short!) | LRU (fixed size) |
| Redis | Redis Cluster | ~8% | 0.5–1ms | 1 hour (data-dependent) | allkeys-lru |
| Database | PostgreSQL buffer pool | ~2% | 5–50ms | Automatic | Automatic (LRU pages) |
Class Summary
Four Topics, One Framework
Cache-Aside vs Write-Through: Cache-aside is the default for 90% of systems (lazy loading, delete on write). Write-through is for consistency-critical data (synchronous double write). Write-behind is for write-heavy metrics (async flush). Always delete cache keys on write, never update — avoid race conditions.
Cache Invalidation: Five strategies: TTL expiry (simplest), delete-on-write (most common), event-driven (best for microservices), version stamping (no explicit deletion), stale-while-revalidate (best UX). Combine TTL + delete-on-write as the production default.
Cache Stampede: Occurs when a popular key expires and thousands of requests hit DB simultaneously. Best solutions: lock + single refill (most effective), jittered TTL (prevents mass expiry), stale-while-revalidate (best UX). Always add jitter to TTLs in production.
Hot Key Problem: One key overwhelms a Redis node with extreme read traffic. Default solution: two-tier cache with local in-process LRU (5s TTL) in front of Redis — reduces Redis load by 99.9%. Also consider key replication and key splitting for extreme cases (>1M RPS).
CDN Architecture: Edge PoPs handle Anycast DNS, TLS termination, WAF/DDoS, caching, and compression. Use fingerprinted URLs for static assets (1-year TTL), s-maxage for dynamic content, and Cache-Control: private for user-specific data. CDN offloads 60–80% of origin traffic and absorbs DDoS attacks.
Want to Land at Google, Microsoft or Apple?
Watch Pranjal Jain's free 30-min training — the exact GROW Strategy that helped 1,572+ engineers go from TCS/Infosys to top product companies with a 3–5X salary hike.