Part 1
Complete Database Quiz — 30 Questions

Target: 24+ correct (80%+). Answers are shown highlighted in green — attempt each question before scrolling.
Scoring Guide
27–30
Excellent — Interview Ready
18–23
Good — Review Weak Areas
12–17
Fair — Re-read In-Class Notes
0–11
Needs Work — Review Pre-Class
Section A: SQL vs NoSQL & Database Types — Q1 to Q8
Question 1
Which property does SQL guarantee that most NoSQL databases do not?
- A) Horizontal scaling
- B) ACID transactions ✓
- C) Flexible schema
- D) High write throughput
Question 2
Which NoSQL type is best for storing user sessions with O(1) lookups?
- A) Document store (MongoDB)
- B) Graph database (Neo4j)
- C) Key-value store (Redis) ✓
- D) Wide-column store (Cassandra)
Question 3
You are designing a social network. Which database is best for "find friends of friends who like X"?
- A) PostgreSQL
- B) Redis
- C) Neo4j ✓
- D) Cassandra
Question 4
Discord stores trillions of messages. Which database type did they choose?
- A) SQL (PostgreSQL)
- B) Document (MongoDB)
- C) Wide-column (Cassandra/ScyllaDB) ✓
- D) Key-value (Redis)
Question 5
What does BASE stand for in NoSQL systems?
- A) Basically Available, Soft state, Eventually consistent ✓
- B) Binary Access, Sorted Entries
- C) Balanced, Available, Scalable, Elastic
- D) Big data, Analytics, Storage, Efficiency
Question 6
Which database would you choose for full-text search across millions of product descriptions?
- A) PostgreSQL
- B) Redis
- C) Elasticsearch ✓
- D) Cassandra
Question 7
Polyglot persistence means:
- A) Using one database for all data
- B) Using multiple databases, each for what it does best ✓
- C) Storing data in multiple languages
- D) Replicating data to multiple regions
Question 8
Which statement about MongoDB is correct?
- A) It uses fixed schemas like PostgreSQL
- B) It stores data as JSON-like documents with flexible schemas ✓
- C) It is a key-value store like Redis
- D) It does not support indexes
Section B: Indexing & Storage Engines — Q9 to Q15
Question 9
Without an index, a query on a table with 10 million rows requires approximately:
- A) 10 comparisons
- B) 1,000 comparisons
- C) 10,000,000 comparisons (full table scan) ✓
- D) 100 comparisons
Question 10
A B-Tree index on a table with 10 million rows requires approximately how many comparisons?
- A) 10,000,000
- B) ~24 (log₂ of 10M) ✓
- C) 1,000
- D) 100,000
Question 11
The leftmost prefix rule for composite indexes means:
- A) The index can only be used starting from the leftmost column ✓
- B) The leftmost column must be a primary key
- C) You can only have one composite index per table
- D) The index is sorted alphabetically left to right
Question 12
Adding an index to a table makes:
- A) Reads faster and writes faster
- B) Reads faster but writes slower ✓
- C) Reads slower and writes faster
- D) No difference to performance
Question 13
LSM-Trees (used by Cassandra) achieve high write throughput because:
- A) They update data in place like B-Trees
- B) They use sequential, append-only writes instead of random I/O ✓
- C) They do not support indexes
- D) They store data only in memory
Question 14
Which index type is best for the query: WHERE email = 'alice@example.com' (exact match only)?
- A) Full-text index
- B) B-Tree index
- C) Hash index (if available) ✓
- D) No index needed
Question 15
A write-heavy IoT system processes 500K inserts/sec. How many indexes should the main data table have?
- A) As many as possible for query flexibility
- B) Minimal — only essential indexes, each one slows writes ✓
- C) Exactly one per column
- D) None — indexes are not needed
Section C: Replication & Partitioning — Q16 to Q23
Question 16
In leader-follower replication, writes go to:
- A) Any server
- B) Only the leader (primary) ✓
- C) Only followers (replicas)
- D) A randomly selected server
Question 17
Asynchronous replication is faster than synchronous because:
- A) It uses a faster network protocol
- B) The leader confirms the write without waiting for followers to acknowledge ✓
- C) It compresses data before sending
- D) It does not actually replicate data
Question 18
A user updates their profile and immediately refreshes but sees the old data. This is most likely caused by:
- A) A bug in the application code
- B) Reading from a follower with replication lag ✓
- C) A network partition
- D) The database crashed
Question 19
Horizontal partitioning (sharding) splits data by:
- A) Columns (different fields per shard)
- B) Rows (different data subsets per shard) ✓
- C) Tables (different tables per database)
- D) Queries (different query types per shard)
Question 20
Which is a BAD partition key for a user-centric application?
- A) user_id
- B) created_at (timestamp) ✓
- C) order_id
- D) tenant_id
Question 21
The celebrity problem (hot partition) occurs when:
- A) All shards have equal traffic
- B) One partition receives disproportionately more traffic than others ✓
- C) A database server is physically too hot
- D) Too many indexes slow down the system
Question 22
Consistent hashing is used in sharding to:
- A) Encrypt data across shards
- B) Minimize data movement when adding or removing shards ✓
- C) Speed up JOIN operations
- D) Ensure ACID transactions across shards
Question 23
When should you shard your database?
- A) Immediately when starting a new project
- B) After exhausting vertical scaling, read replicas, and caching ✓
- C) Whenever you have more than 100 tables
- D) When using NoSQL databases
Section D: Read/Write Patterns & Architecture — Q24 to Q30
Question 24
A system with 95% reads and 5% writes is best optimized with:
- A) Sharding across many databases
- B) Aggressive caching (Redis + CDN) and read replicas ✓
- C) LSM-Tree storage engine
- D) Removing all indexes
Question 25
For a write-heavy IoT platform (500K writes/sec), the best database engine is:
- A) B-Tree (PostgreSQL)
- B) LSM-Tree (Cassandra/ScyllaDB) ✓
- C) Graph (Neo4j)
- D) Key-value only (Redis)
Question 26
CQRS separates:
- A) Read and write operations into different optimized databases ✓
- B) SQL and NoSQL into separate networks
- C) Indexes from tables
- D) Primary keys from foreign keys
Question 27
In a read-heavy e-commerce system, which caching pattern is most appropriate?
- A) Write-through (write to cache and DB simultaneously)
- B) Cache-aside (check cache first, populate on miss) ✓
- C) Write-behind (write to cache, async flush to DB)
- D) No caching (always read from DB)
Question 28
Denormalization helps read-heavy systems because:
- A) It reduces disk space usage
- B) It avoids expensive JOIN operations by pre-computing related data ✓
- C) It makes writes faster
- D) It enforces data integrity
Question 29
In a payment system, SELECT ... FOR UPDATE is used to:
- A) Speed up the query
- B) Lock the row to prevent concurrent modifications (e.g., double spending) ✓
- C) Delete the row after reading
- D) Update the row without a WHERE clause
Question 30
The ideal scaling ladder for a growing application is:
- A) Shard first, then add replicas, then add cache
- B) Single DB → Vertical scaling → Read replicas → Caching → Sharding ✓
- C) Cache everything from day one, never use a database
- D) Start with NoSQL, migrate to SQL when stable
Part 2
Design: E-Commerce Database System
This exercise applies every database concept from Class 5 to design a complete data layer for an e-commerce platform like a simplified Amazon or Flipkart. Requirements: 10 million users, 1 million products, 100K orders per day, 1 million cart operations per day. Must support ACID transactions for payments, full-text search for products, real-time inventory management, and scale from launch to millions of users.
The schema must support: user registration and login, product browsing and search, cart management, order placement with inventory checks, payment processing with idempotency, and order history queries.
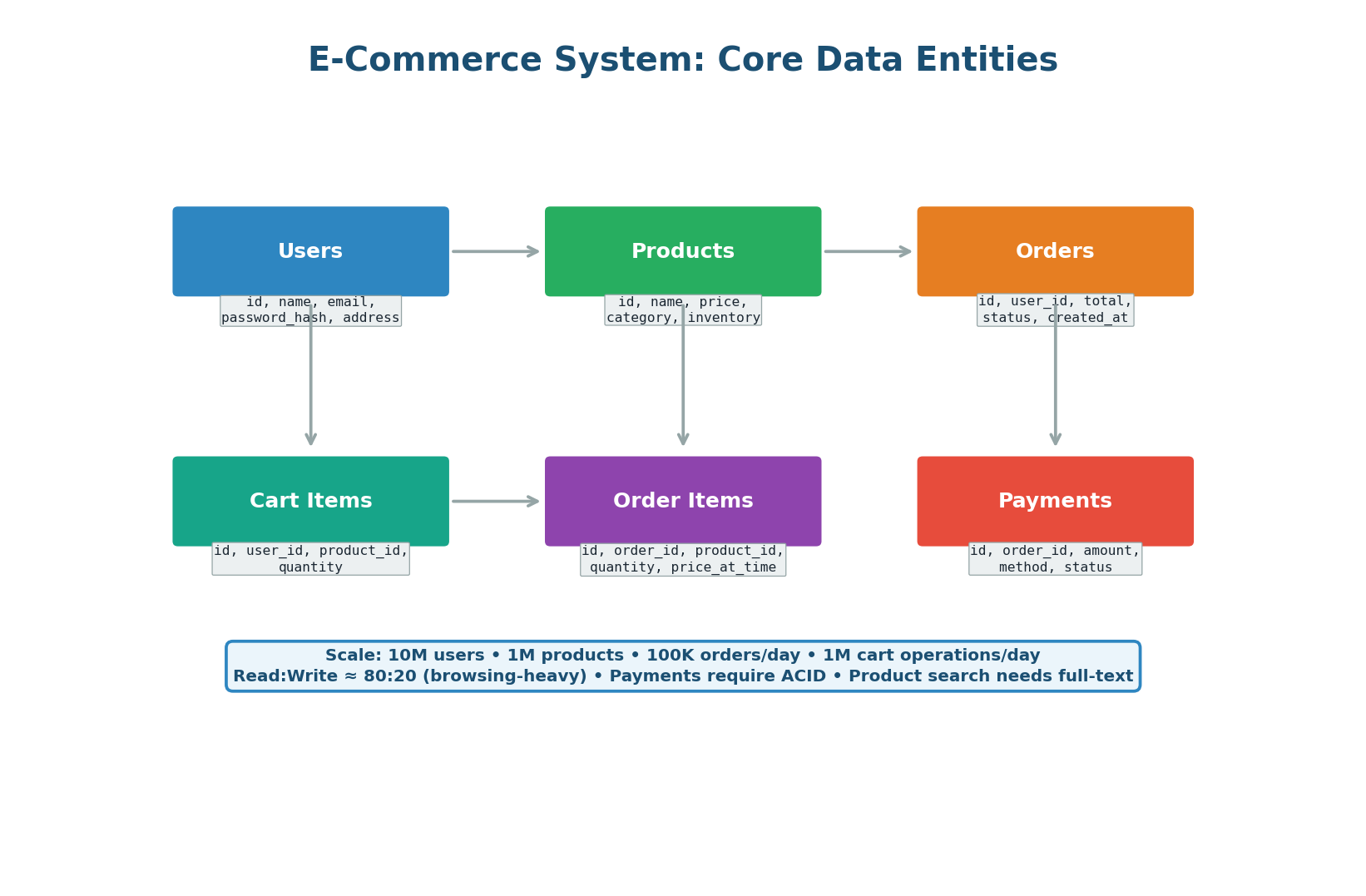
Figure 1: Six core data entities — Users, Products, Orders, Order Items, Cart Items, Payments

Figure 2: Complete database schema with all tables, columns, data types, and constraints
Key Design Decisions:
- UUIDs as Primary Keys: Globally unique, do not leak business volume, and work across shards without coordination. Trade-off: larger (16 bytes vs 4 bytes for INT) and random insertion into B-Tree indexes causes page splits. Mitigation: use UUIDv7 (time-sorted).
price_at_time in order_items: Store the price at the time of purchase, not a join to the current price. If a product price changes from $99 to $129 after a user ordered it, their order must still show $99. Never compute order totals by joining to the live product price.idempotency_key in payments: A UNIQUE constraint prevents duplicate payments at the database level even if the application retries. This prevents double charges even if the application layer misses it.- Separate addresses table: Users can have multiple addresses (home, office). A separate table with an
is_default flag allows flexible address management and reuse across orders.
The index strategy is driven by access patterns. Most frequent queries: user login (email lookup), user's order history (user_id + created_at), product search (full-text), category browsing (category_id), payment idempotency checks (idempotency_key).

Figure 3: Index plan matching each core query pattern to the optimal index type
3
Database Selection (Polyglot Persistence)
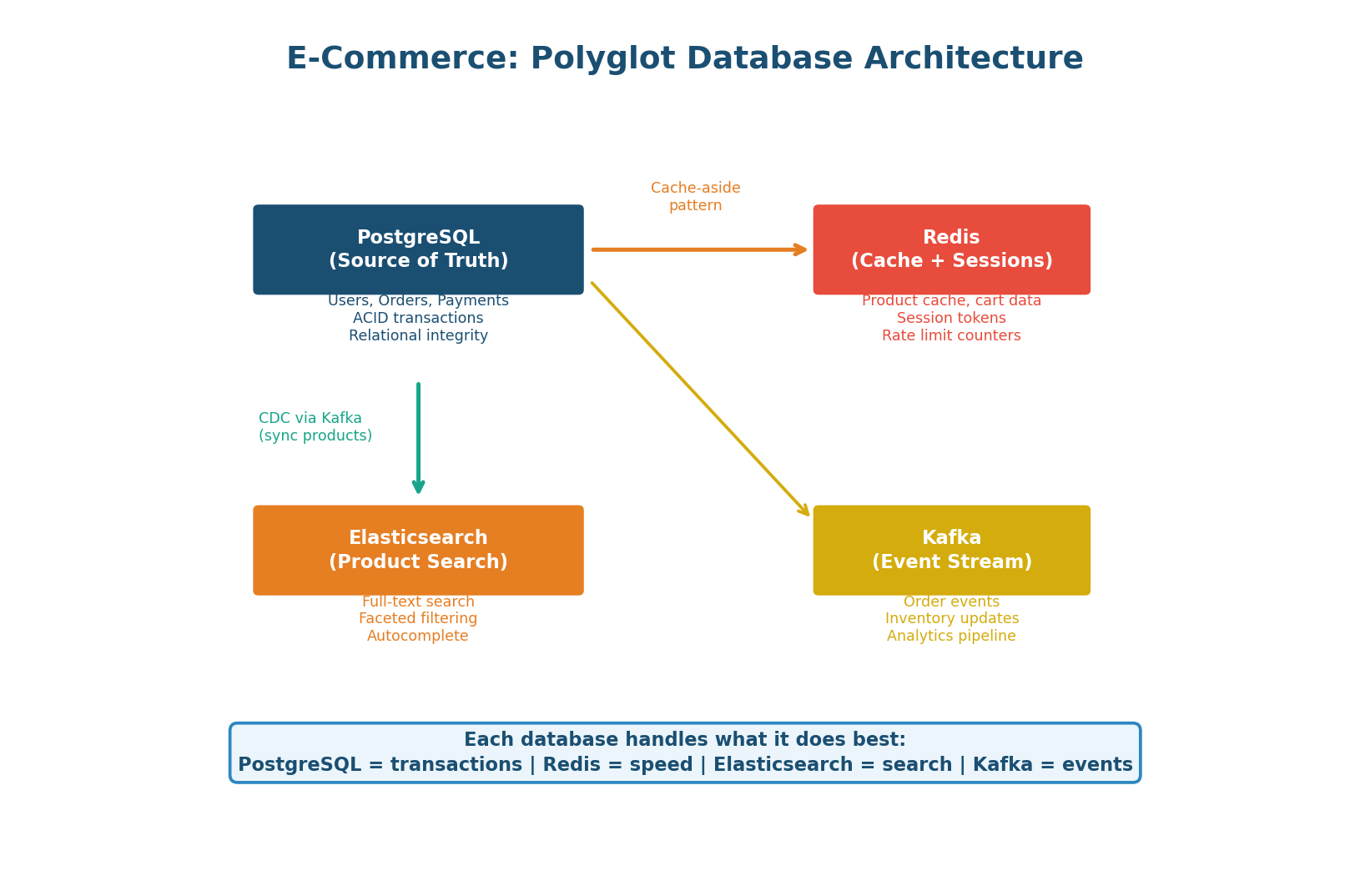
Figure 4: Four databases working together — PostgreSQL (truth), Redis (speed), Elasticsearch (search), Kafka (events)
- PostgreSQL (Source of Truth): Stores users, orders, payments, and addresses. ACID transactions ensure that order placement (inventory decrement + order creation + payment) is atomic. Read replicas handle read-heavy queries.
- Redis (Cache + Sessions + Cart): Caches product catalog (24h TTL), stores user sessions (30min TTL), and manages shopping carts. Cart data is written to PostgreSQL only at checkout.
- Elasticsearch (Product Search): Full-text search, faceted filtering, autocomplete. Product data synced from PostgreSQL via Kafka CDC (Change Data Capture).
- Kafka (Event Streaming): Order events trigger inventory updates, email notifications, analytics pipeline, search index updates, and recommendation engine updates. Decouples producers from consumers for resilient event processing.
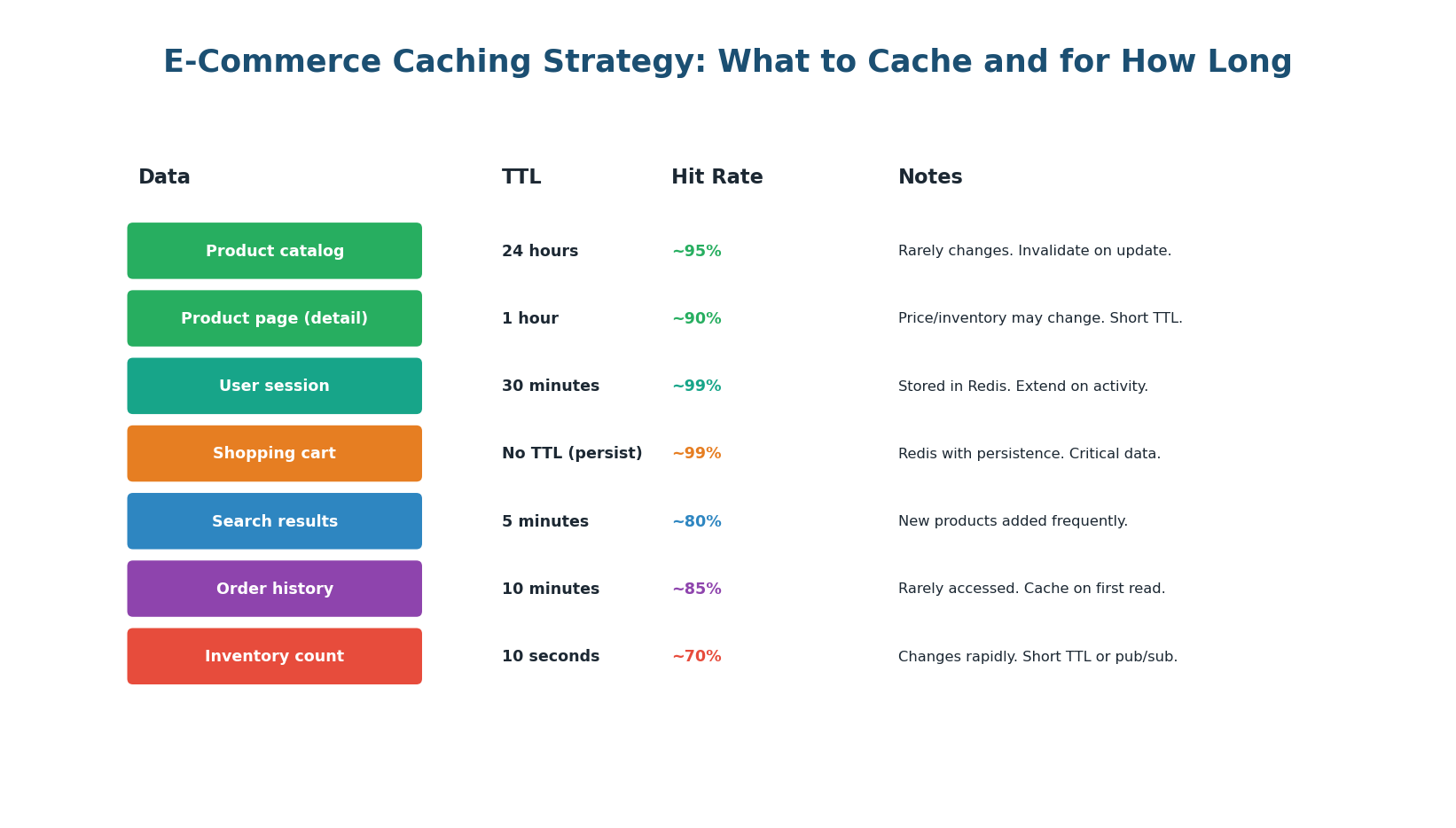
Figure 5: What to cache and for how long — each data type has a TTL based on how frequently it changes
The caching strategy follows the cache-aside pattern: check Redis first; on miss, query PostgreSQL, store in Redis, return result. On writes, write to PostgreSQL and invalidate the Redis key.
Critical: Never Trust Cache for Inventory at Checkout
Inventory changes rapidly with every purchase. A long cache TTL risks overselling. Use a short TTL (10 seconds) or pub/sub invalidation for display. For the final inventory check at checkout, always read from PostgreSQL with SELECT FOR UPDATE — never trust the cache for the transactional inventory check.
5
Order Transaction Flow (ACID)
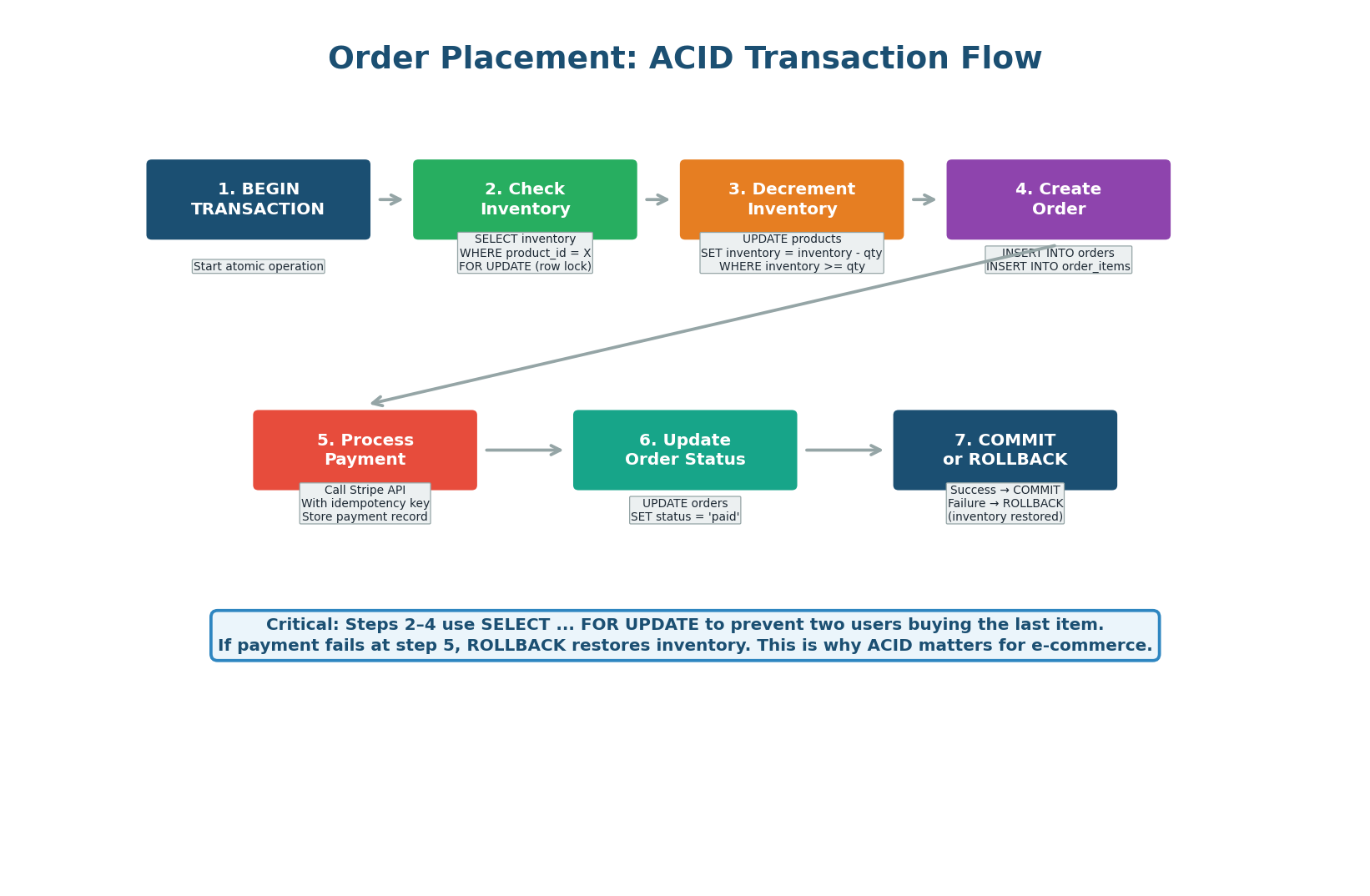
Figure 6: The 7-step ACID transaction flow for placing an order — including row-level locking for inventory
The order placement flow must be atomic: either all steps succeed (inventory decremented + order created + payment processed) or all steps roll back. This is implemented as a single PostgreSQL transaction.
The key technique is SELECT ... FOR UPDATE on the inventory row. This places an exclusive lock, preventing any other transaction from reading or modifying it until the current transaction completes. This prevents the classic race condition where two users simultaneously buy the last item: without the lock, both would see inventory=1, both would decrement to 0, and the store would oversell.
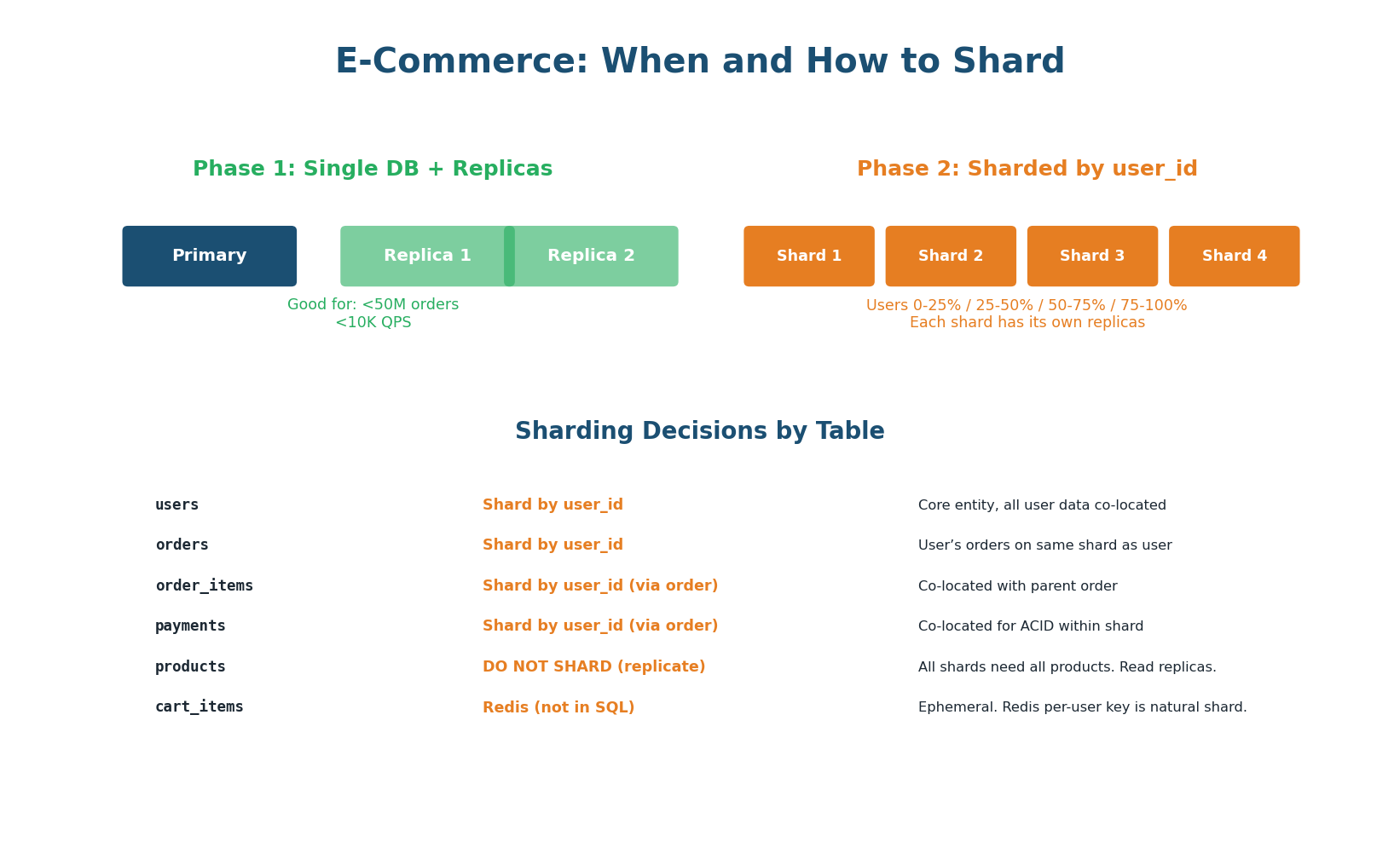
Figure 7: Phase 1 uses single DB + replicas + caching. Phase 2 shards by user_id with products replicated to all shards.
Follow the database scaling ladder. Start with a single PostgreSQL instance (handles up to ~50K QPS). Add read replicas when reads exceed capacity. Add Redis caching to offload 90%+ of reads. Only shard when data volume or write throughput exceeds a single machine.
When sharding becomes necessary: shard by user_id. This co-locates a user's orders, order items, and payments on the same shard — keeping ACID transactions local to one shard (no distributed transactions). Products are replicated to all shards (every shard needs the full catalog). Cart data stays in Redis, which is naturally sharded by user.
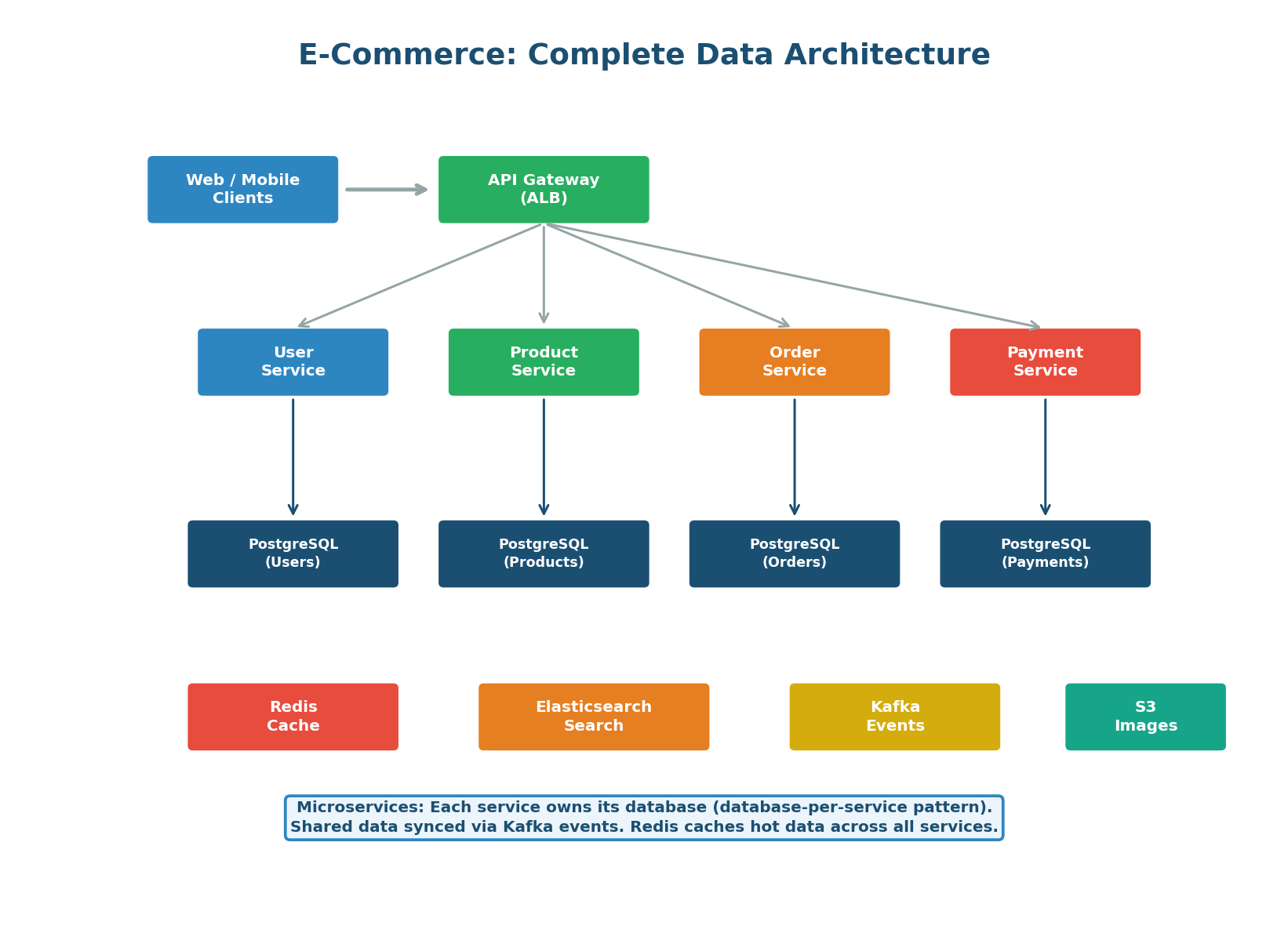
Figure 8: The complete e-commerce data architecture with microservices, each owning its own database
Answer Key
Full Explanations for All 30 Questions
Section A: SQL vs NoSQL & Database Types
Q1: B — SQL databases guarantee ACID transactions. Most NoSQL databases offer BASE (eventual consistency) instead, sacrificing strong consistency for availability and scale.
Q2: C — Key-value stores like Redis provide O(1) lookup by key, perfect for session data where you always query by session_id. Document stores can also work but are overkill for simple key-value access.
Q3: C — Neo4j (graph database) excels at traversing relationships. "Friends of friends who like X" requires multiple relationship hops, which is O(1) per hop in a graph DB but requires expensive recursive JOINs in SQL.
Q4: C — Discord uses Cassandra (now migrated to ScyllaDB). Wide-column stores handle massive write throughput and time-series data (messages ordered by timestamp) efficiently.
Q5: A — BASE = Basically Available, Soft state, Eventually consistent. It is the NoSQL counterpart to ACID, accepting weaker consistency for better availability and performance.
Q6: C — Elasticsearch is purpose-built for full-text search with relevance scoring, fuzzy matching, faceted filtering, and autocomplete. PostgreSQL has basic full-text search but Elasticsearch is far more capable at scale.
Q7: B — Polyglot persistence means using multiple database technologies, each for what it does best: PostgreSQL for transactions, Redis for caching, Elasticsearch for search, Cassandra for time-series.
Q8: B — MongoDB stores data as BSON (Binary JSON) documents with flexible schemas. Each document can have different fields. It supports rich queries and indexes on any field.
Section B: Indexing & Storage Engines
Q9: C — Without an index, the database must scan every row (full table scan). For 10M rows, that means 10M comparisons to find one matching row.
Q10: B — A B-Tree index provides O(log N) lookups. log₂(10,000,000) ≈ 23.25, so approximately 24 comparisons to find any row among 10 million. That is a 400,000x improvement.
Q11: A — A composite index on (A, B, C) can be used for queries on A, or (A, B), or (A, B, C). It CANNOT be used for queries on B alone or C alone — only starting from the leftmost column.
Q12: B — Indexes speed up reads (O(log N) instead of O(N)) but slow down writes (each INSERT/UPDATE must update every index on the table). Every index is a write amplifier.
Q13: B — LSM-Trees write to an in-memory buffer (memtable) and flush sorted data sequentially to disk (SSTables). Sequential I/O is 5–10x faster than the random I/O required by B-Tree page updates.
Q14: C — Hash indexes provide O(1) exact-match lookups, faster than B-Tree O(log N) for pure equality queries. B-Tree works too but Hash is theoretically optimal for WHERE col = ?.
Q15: B — For write-heavy tables, minimize indexes. Each index multiplies write overhead. Only index columns essential for queries. Consider writing raw data and indexing asynchronously.
Section C: Replication & Partitioning
Q16: B — In leader-follower replication, ALL writes go exclusively to the leader. The leader then replicates changes to followers. Followers are read-only copies.
Q17: B — With async replication, the leader confirms the write to the client immediately without waiting for followers. Sync replication waits for at least one follower ACK before confirming.
Q18: B — Classic replication lag symptom. The write went to the leader, but the read was served by a follower that had not yet received the update. Solution: route a user's own reads to the leader (read-your-writes consistency).
Q19: B — Horizontal partitioning splits rows across shards. Each shard has the full schema but different subsets of data. Vertical partitioning splits columns.
Q20: B — created_at is a terrible partition key because all new writes go to the latest time partition (hotspot). user_id, order_id, and tenant_id all have high cardinality and even distribution.
Q21: B — The celebrity problem occurs when one key (e.g., a celebrity's user_id) generates disproportionate traffic, overwhelming the shard containing that key while others sit idle.
Q22: B — Consistent hashing minimizes data movement when shards are added or removed. Only ~1/N of keys need to move instead of nearly all keys with simple mod-N hashing.
Q23: B — Sharding adds massive complexity and should be the last resort. The scaling ladder: single DB → vertical scaling → read replicas → caching → sharding.
Section D: Read/Write Patterns & Architecture
Q24: B — A 95% read system benefits most from aggressive caching (Redis handles most reads at <1ms) and read replicas. Sharding is overkill for a read-heavy system.
Q25: B — LSM-Tree engines (Cassandra, ScyllaDB) achieve 5–10x higher write throughput through sequential, append-only writes. This is exactly what 500K writes/sec demands.
Q26: A — CQRS (Command Query Responsibility Segregation) uses separate databases for writes (optimized for transactions) and reads (optimized for queries), synchronized via events.
Q27: B — Cache-aside is the most common pattern for read-heavy systems: check cache first, on miss query DB and populate cache. Write-through writes to both simultaneously (good for write consistency).
Q28: B — Denormalization pre-computes JOINs and stores the result. Reads avoid expensive JOIN operations at query time, trading write complexity and storage for faster reads.
Q29: B — SELECT FOR UPDATE places an exclusive row lock, preventing other transactions from reading or modifying the row until the lock is released. Essential for inventory management to prevent overselling.
Q30: B — The correct order starts simple and adds complexity only when needed: Single DB → Bigger machine → Read replicas → Cache layer → Sharding (last resort).
Design Checklist
12-Point Verification for E-Commerce DB Design

Figure 9: 12-point checklist covering every aspect of the e-commerce database design — use this in interviews
How to Use This in an Interview
When asked to design a database for an e-commerce system, walk through all 7 steps: schema → indexes → polyglot selection → caching → transaction flow → scaling → architecture. Call out every key decision: price_at_time, idempotency_key, SELECT FOR UPDATE for inventory, cache-aside with short TTL for inventory, shard by user_id for co-location. Finishing with the design checklist shows thoroughness that separates senior candidates from the rest.
Want to Land at Google, Microsoft or Apple?
Watch Pranjal Jain's free 30-min training — the exact GROW Strategy that helped 1,572+ engineers go from TCS/Infosys to top product companies with a 3–5X salary hike.
DSA + System Design roadmap
1:1 mentorship from ex-Microsoft
1,572+ placed · 4.9★ rated
Watch Free Training →
