
What's Inside
Part 1
Complete Distributed Systems Quiz — 30 Questions

Section A · 8 Questions
Concurrency & Locks
A race condition = behavior depends on timing of unsynchronized concurrent operations. Two users reading simultaneously is only a race if their subsequent writes conflict without coordination.
Atomic SQL: UPDATE SET qty = qty-1 WHERE qty > 0. If affected_rows = 0, item is out of stock. The database handles concurrency atomically. No application-level locks needed.
SETNX = SET if Not eXists. Only one process can set the key. Others see it exists and know the lock is held. Use with TTL for auto-release on crash.
Without TTL, if the lock holder crashes, the lock is held forever (deadlock). TTL auto-releases after a timeout, allowing another process to acquire.
Fencing tokens: each lock acquisition gets a monotonically increasing token. Storage rejects writes with token < highest seen. Prevents a stale holder (whose lock expired during a GC pause) from overwriting.
Optimistic locking reads the version, then writes with WHERE version = N. If another process changed the version in between, the write affects 0 rows, and the application retries.
Redlock acquires on 5 independent Redis instances. If majority (3+) succeed within timeout, lock is held. Survives up to 2 Redis node failures.
SELECT ... FOR UPDATE in PostgreSQL:SELECT FOR UPDATE places an exclusive row lock. Other transactions that try to read or write those rows must wait until the lock-holding transaction commits or rolls back.
Section B · 7 Questions
Replication & Partitioning
Single-leader: ALL writes go to the leader. It replicates to followers. Followers are read-only. Simplest topology, most common (PostgreSQL, MySQL, MongoDB).
Leaderless uses quorum: W+R>N guarantees read-write overlap. With N=3, W=2, R=2: at least one of the 2 read nodes has the latest write (from the 2 write nodes).
W=2, R=2, N=3. If 1 node fails: writes still succeed (2 of 2 remaining), reads still succeed (2 of 2 remaining). If 2 fail: W=2 but only 1 node available, writes fail.
Partitioning gives write scalability (N shards = N× writes) but makes cross-shard joins slow (scatter-gather) and cross-shard transactions require 2PC (fragile).
user_id key co-locates all user data on one shard. User's orders, payments, profile = same shard = local ACID transactions. The primary access pattern is user-centric.
Multi-leader: each geographic region has a local leader accepting writes. Users get low-latency writes to their nearest leader. Cross-region sync is async.
Multi-leader = multiple writers = write conflicts. Two leaders may accept conflicting updates to the same row. Must resolve via LWW, CRDTs, or application logic.
Section C · 8 Questions
Failures & CAP Theorem
Network partition = network splits the cluster into groups that cannot communicate. Nodes in each group are alive but isolated from each other.
CAP: during a partition, choose Consistency (reject writes from minority, no stale data) or Availability (accept writes on both sides, risk conflicting data).
CP system rejects writes from the minority partition (fewer than N/2+1 nodes). Only the majority side accepts writes. This prevents conflicting writes.
Split brain: network partition → each side elects its own leader → two leaders accepting writes → conflicting data. Prevented by majority quorum.
Majority quorum (N/2+1 votes) for leader election. With 5 nodes, need 3 votes. A partition of 2 nodes cannot elect a leader (only has 2 votes).
Cascading failure: DB slow → app timeouts → thread pool exhausted → retries → DB overwhelmed → crash. One failure triggers a chain of failures.
Circuit breaker: after N failures, immediately return error without calling the failing service. This stops the cascade — no retries hitting the already-struggling service.
4 nodes needs 3 for majority, tolerates 1 failure. 3 nodes needs 2, also tolerates 1. The 4th node adds cost without improving fault tolerance.
Section D · 7 Questions
Consensus & Consistency
Raft commits when a majority (N/2+1) of nodes have the log entry. This ensures even if the leader crashes, the committed entry exists on a majority and survives.
Never implement consensus yourself. Use etcd, ZooKeeper, or Consul. These are battle-tested for edge cases you will never think of. Consensus algorithms are notoriously hard to get right.
Linearizable = every read returns the most recent write, as if there is only one copy of the data. The strongest consistency guarantee. Requires quorum reads/writes.
Eventual consistency = if no new writes occur, all replicas will eventually converge to the same value. They may temporarily disagree, but they eventually agree.
Per-operation: strong for financial writes (payments, inventory), read-your-writes for user-facing state (profile), eventual for most reads (feed, catalog). This hybrid is what production systems use.
RYW ensures a user sees their own recent writes. After updating their name to 'Alice', their next read returns 'Alice' (routed to leader). Other users may still see the old name briefly.
LWW: compare timestamps, keep the value with the highest timestamp. The other value is silently discarded. Simple but lossy. OK for metrics, not for financial data.
Part 2
Strong vs Eventual Consistency Trade-offs
The Core Trade-off in Every System Design
Every distributed system must choose, for every operation, how consistent the data needs to be. Strong consistency guarantees that every read returns the latest write, but it is slower and less available. Eventual consistency allows reads from any replica (fast, available) but the data might be stale. The art of system design is choosing the right level for each operation — not applying one level to the entire system.

The Consistency-Latency Spectrum
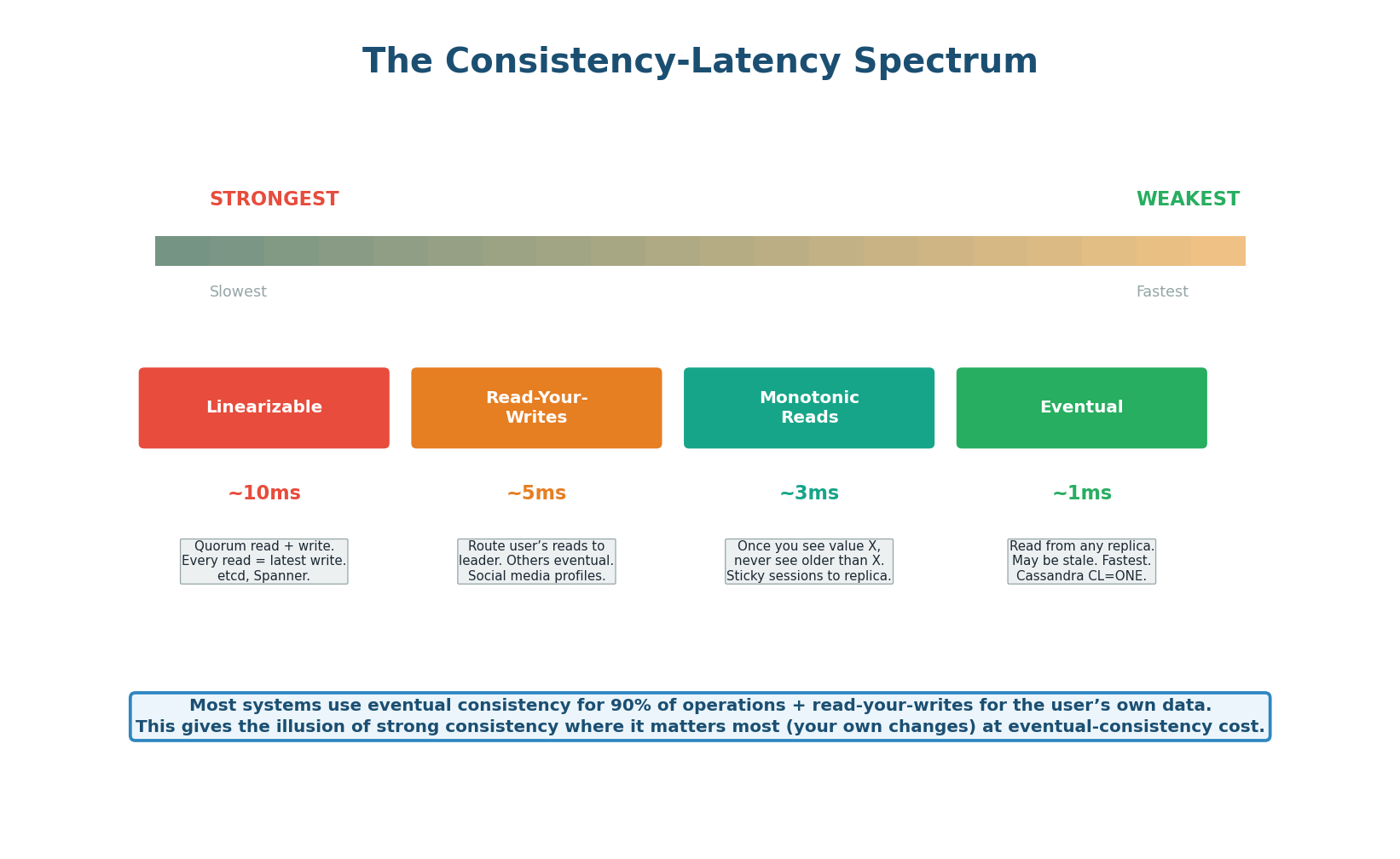
The spectrum is not binary (strong vs eventual). There are intermediate levels that provide useful guarantees at lower cost than full linearizability. Read-your-writes ensures a user always sees their own recent changes (route their reads to the leader for a few seconds after writing). Monotonic reads ensure a user never sees data go backwards (sticky session to one replica). These intermediate levels cover 90% of use cases without the latency cost of full linearizability.
Per-Operation Consistency: The Right Choice for Each
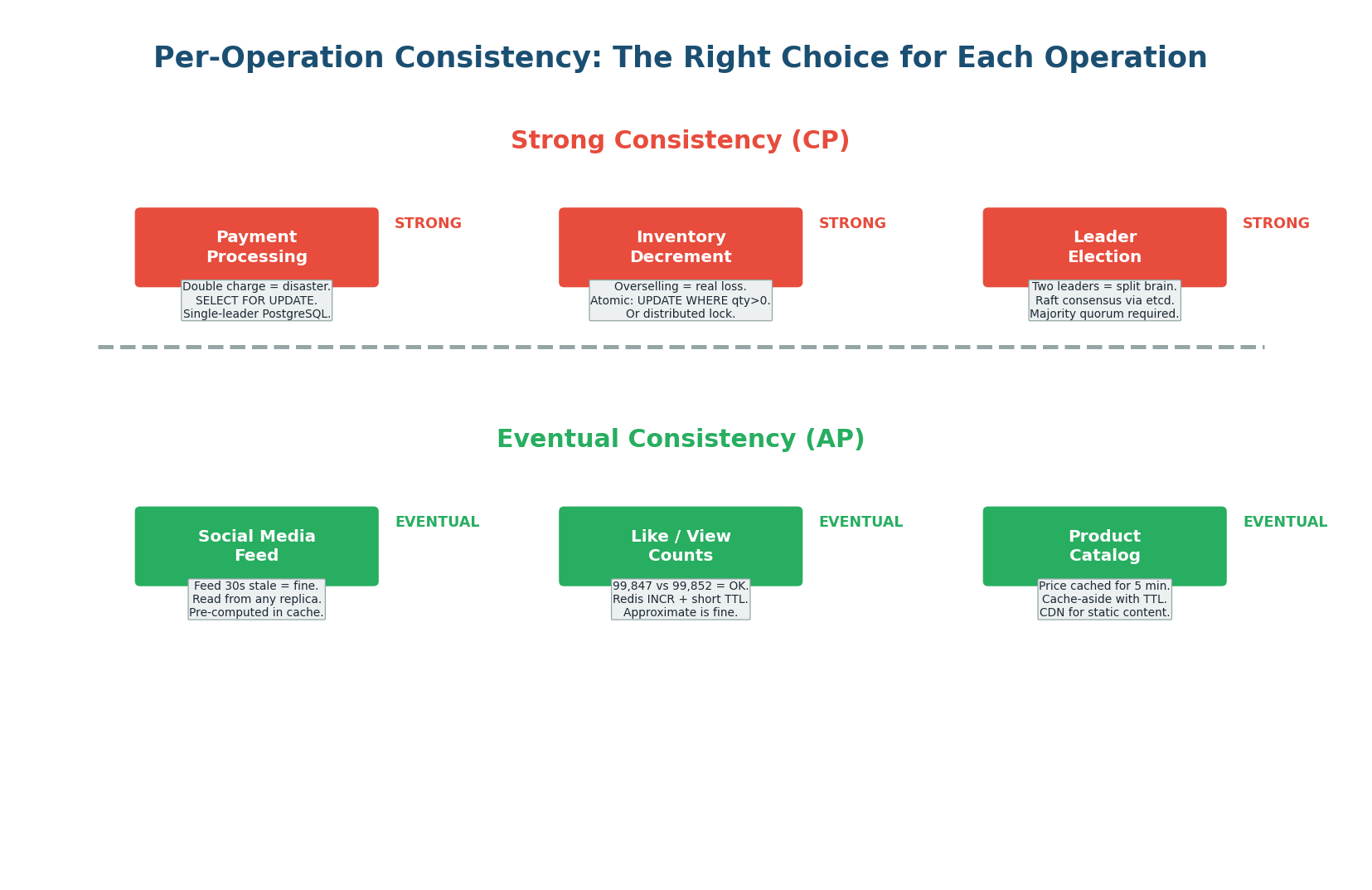
The most common interview mistake is choosing one consistency level for the entire system. The correct approach is per-operation: list every read and write operation, then classify each as requiring strong, read-your-writes, or eventual consistency. This hybrid approach gives you correctness where it matters (payments) and performance everywhere else (feeds, catalogs, counts).
Never say "I'll use strong consistency everywhere" or "I'll use eventual consistency everywhere." The first kills performance. The second risks data loss on critical operations. Always say: "For X operation I need strong because..., for Y I can use eventual because..."
Read-Your-Writes: The Practical Middle Ground

Read-your-writes (RYW) is the most important intermediate consistency level. It guarantees that a user always sees the effect of their own recent writes, while other users may see eventual consistency. This covers the most critical UX requirement: when a user updates their name, they see the new name immediately. Other users seeing the old name for 30 seconds is acceptable.
1. Route to leader after write: After a user writes, set a flag (Redis key user:{id}:wrote_at = timestamp). For the next 10 seconds, route that user's reads to the leader. After 10 seconds, replication has caught up, so reads go back to replicas. Simple and effective.
2. Session-sticky replica: Assign each user to a specific replica via consistent hashing (hash(user_id) % num_replicas). All reads for that user go to the same replica. Once that replica receives the write via replication, the user sees it. Slightly slower than routing to leader but avoids leader overload.
3. Client-side timestamp: The client includes its last write timestamp in every read request. The server checks if the serving replica's data is at least as fresh as that timestamp. If not, it either waits for replication or routes to the leader. This is the most precise approach, used by DynamoDB's session consistency.
Monotonic Reads: Never Go Backwards

Monotonic reads guarantee that once a user has seen a value, they never see an older value in subsequent reads. Without this, a user might see 10 comments on a post, refresh, and see only 7 (they hit a staler replica). This "time travel" effect is confusing and frustrating. The solution is simple: use sticky sessions (hash user_id to a consistent replica) so all reads go to the same replica, which only moves forward in time.
Real-World Application: E-Commerce Consistency Map
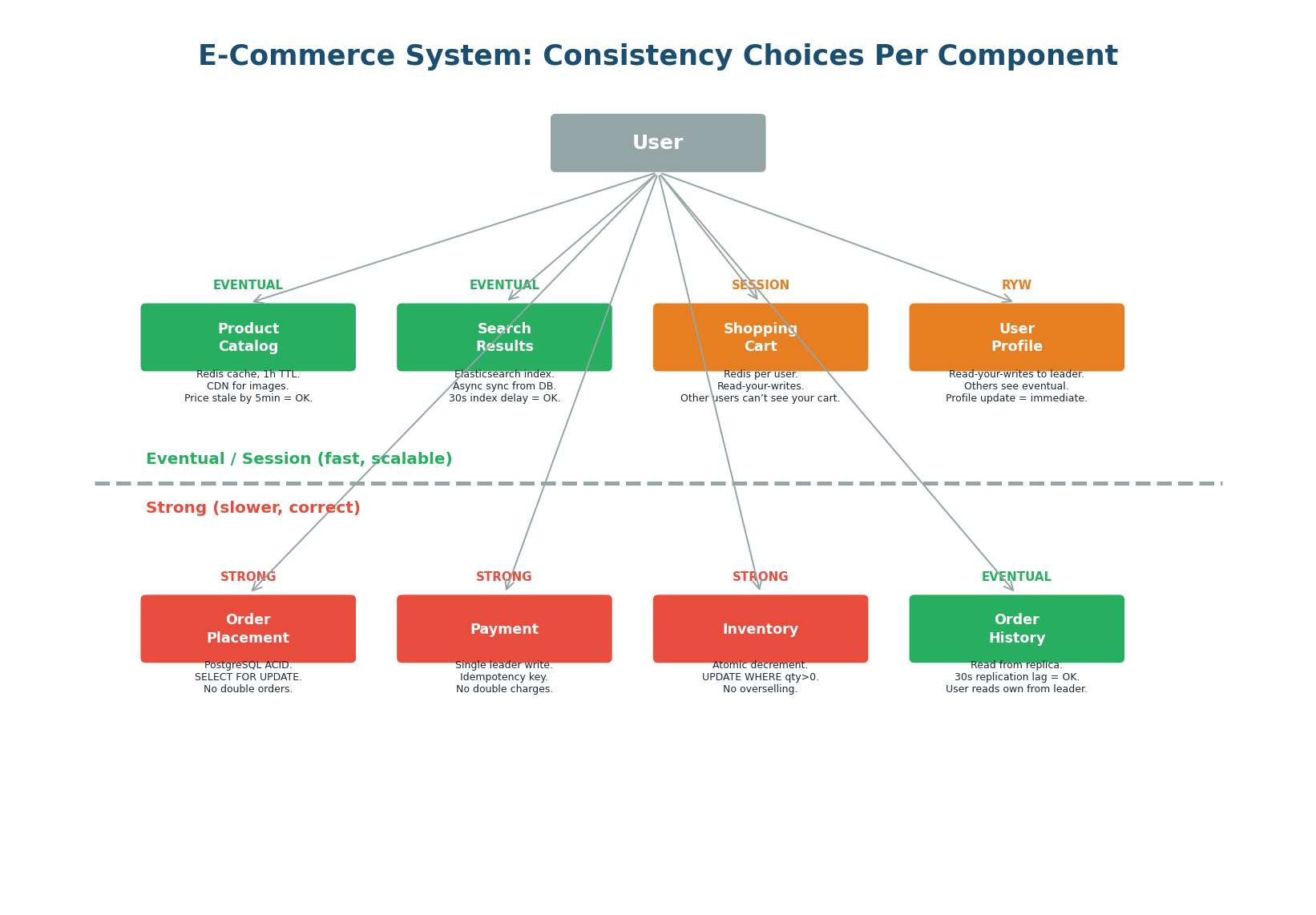
An e-commerce system demonstrates the hybrid approach perfectly. Above the dashed line: Product Catalog, Search Results, Shopping Cart, and User Profile all use eventual or session consistency — they are read-heavy, tolerate brief staleness, and benefit from caching and replicas for low latency. Below the dashed line: Order Placement, Payment, and Inventory all require strong consistency — they involve money, finite resources, and operations where errors cause real-world harm.
Common Anti-Patterns
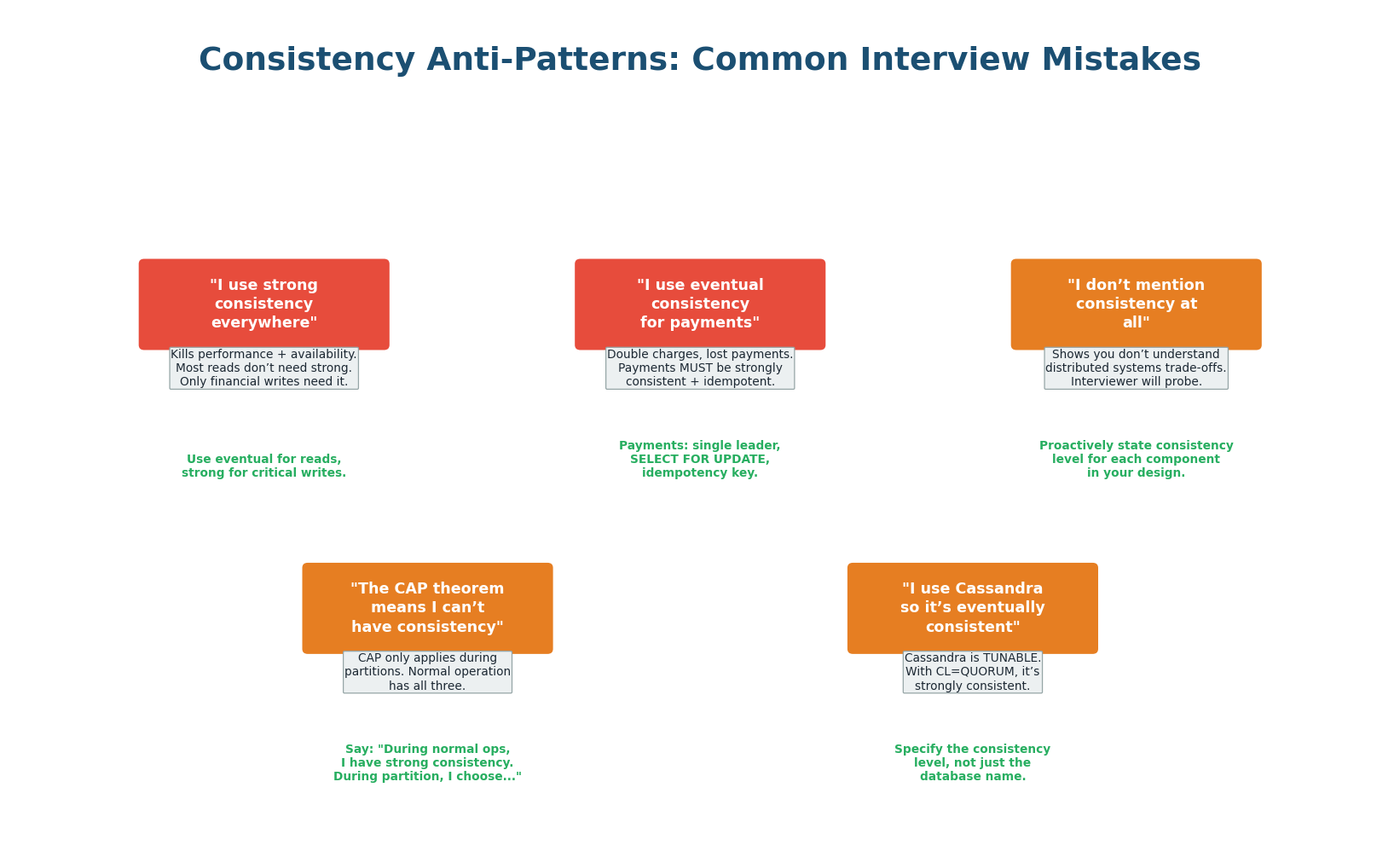
The most common anti-pattern is applying one consistency level to the entire system. Saying "I use strong consistency everywhere" kills performance and availability for no benefit (most reads don't need it). Saying "I use eventual consistency for payments" is dangerous (double charges). The second most common mistake is not mentioning consistency at all, which signals you do not understand distributed systems trade-offs. Always proactively state consistency levels per component.
Implementation Reference
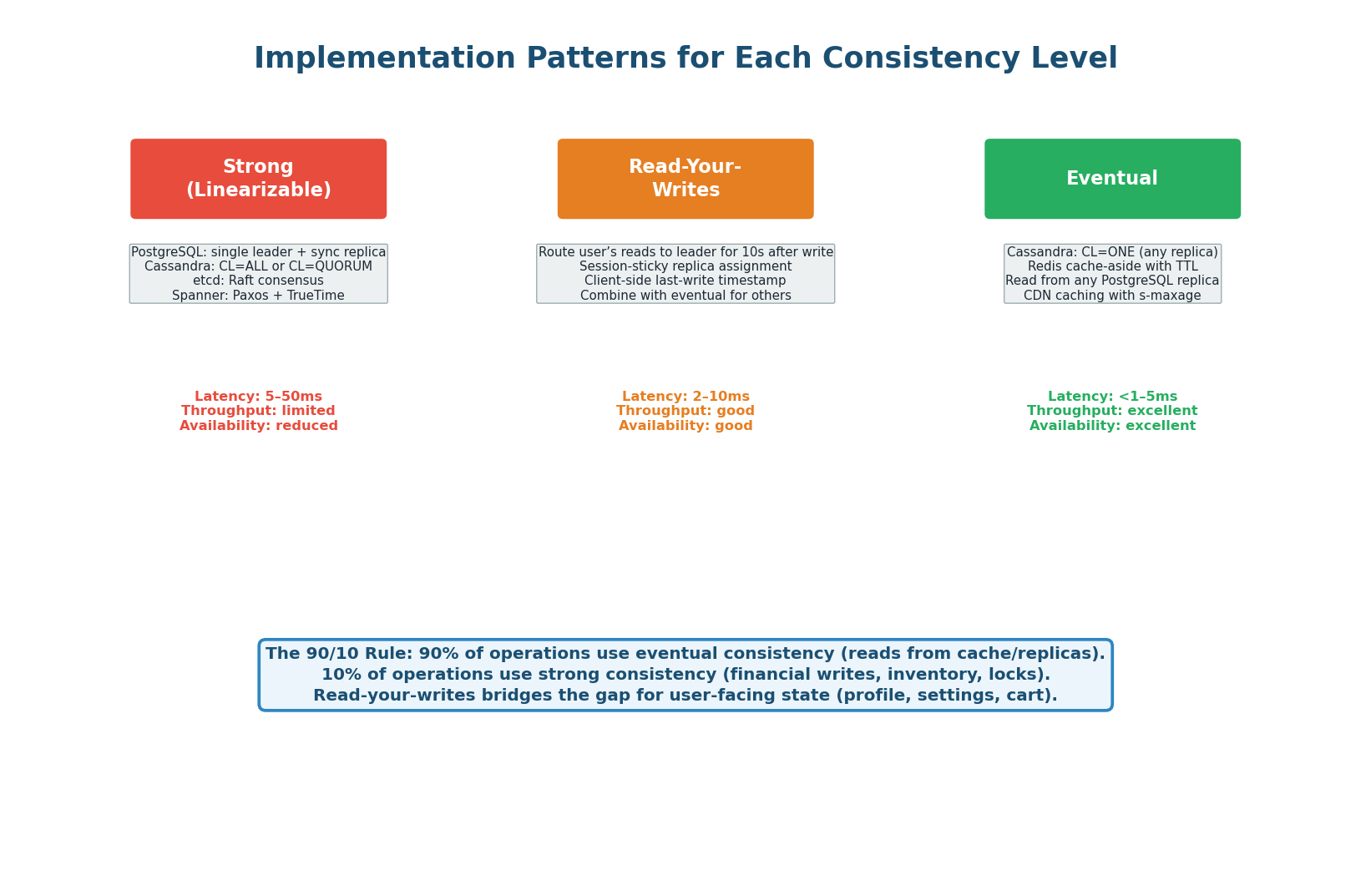
| Pattern | Technologies | Latency | Use When |
|---|---|---|---|
| Strong (Linearizable) | PostgreSQL leader, etcd, ZooKeeper | ~10ms | Payments, inventory, leader election |
| Read-Your-Writes | Redis flag + route to leader; sticky replica | ~2–5ms | Profile updates, settings, user-visible state |
| Eventual | DynamoDB, Cassandra, CDN cache | ~1ms | Feeds, catalogs, counters, search results |
Design Checklist

For every component in your design, explicitly state: "For [operation], I'll use [strong/eventual/read-your-writes] consistency because [reason]. This means [technology choice and trade-off]."
Example: "For inventory deduction, I'll use strong consistency with UPDATE WHERE qty > 0 because overselling causes real-world harm. For the product catalog, I'll use eventual consistency via CDN caching because a 60-second stale price is acceptable and reduces database load by 95%."
Want to Land at Google, Microsoft or Apple?
Watch Pranjal Jain's free 30-min training — the exact GROW Strategy that helped 1,572+ engineers go from TCS/Infosys to top product companies with a 3–5X salary hike.