
What's Inside
Concept 1
Why Distributed Systems Are Hard
A single-machine program is predictable: one process, one clock, no network. When you move to distributed systems — multiple machines communicating over a network — three fundamental challenges emerge that do not exist on a single machine. Every distributed algorithm, from leader election to consensus to distributed locking, exists to cope with these three demons.
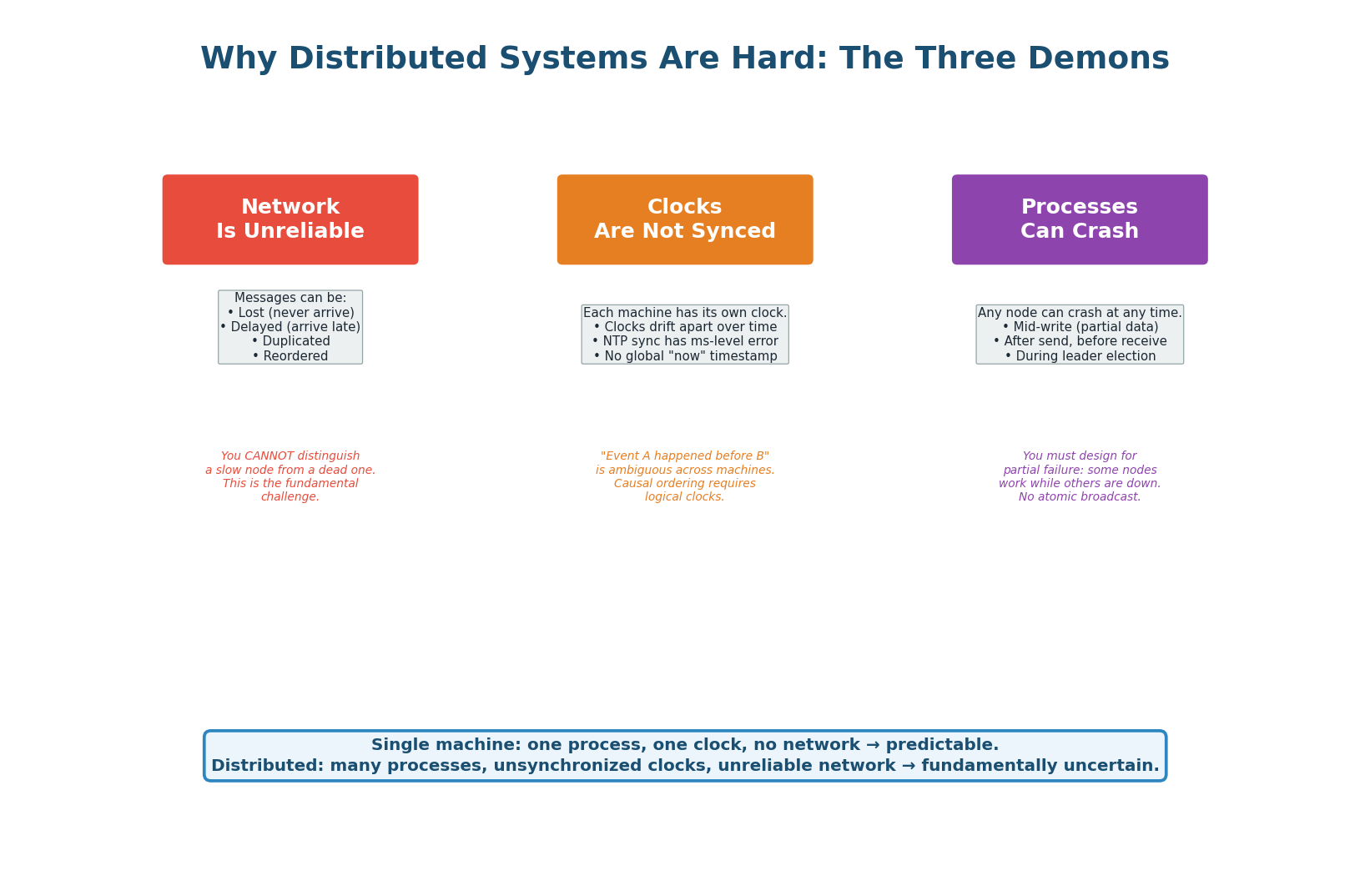
The Network Is Unreliable
Messages between machines can be lost, delayed, duplicated, or reordered. When Node A sends a message to Node B and does not receive a response, it cannot distinguish between: Node B is dead, the network dropped the request, the network dropped the response, or Node B is alive but very slow. This ambiguity is the source of most distributed system bugs.
The FLP theorem proves that in an asynchronous system with even one faulty process, there is no deterministic algorithm that guarantees consensus. This is why every real consensus system (Raft, Paxos) uses timeouts and probabilistic approaches rather than guarantees.
Clocks Are Not Synchronized
Each machine has its own physical clock that drifts independently. NTP can synchronize clocks to within a few milliseconds — but that is not good enough for ordering events across machines. If Machine A records an event at 10:00:00.001 and Machine B records an event at 10:00:00.002, you cannot conclude that A's event happened first — the clock difference might be 5ms. This is why distributed systems use logical clocks (Lamport timestamps, vector clocks) instead of wall-clock time for ordering events.
Processes Can Crash at Any Time
Any node can crash at any moment: mid-write, mid-election, mid-replication. You must design every operation to be safe even under partial failure. If 3 of 5 nodes are alive, the system must still function correctly. This is why distributed algorithms require majority quorums: 3 of 5 nodes (majority) must agree for an operation to succeed, ensuring that even if 2 nodes crash, the remaining 3 have enough information to continue.
Two armies need to coordinate an attack, communicating via messengers who can be captured (messages lost). General A sends "Attack at dawn." Did General B receive it? B sends "Acknowledged." Did A receive the ACK? A sends "ACK of your ACK." This recurses infinitely — neither general can ever be certain the other will attack.
The lesson: you cannot achieve perfect agreement over an unreliable network. Every distributed protocol accepts this and designs around it using quorums, retries, and timeouts.
Concept 2
Concurrency & Race Conditions
A race condition occurs when the behavior of a system depends on the timing of events that are not properly synchronized. In distributed systems, race conditions are especially dangerous because operations happen on different machines with network delays, making coordination harder than on a single machine with shared memory.

The classic example: an e-commerce site has 1 item in stock. User A and User B both click "Buy" at the same time. Both servers read inventory=1, both decide it is available, both decrement to 0, and both confirm the purchase. Two items sold, but only one existed. This is called a lost update — one update overwrites the other because neither was aware of the other's read.
Four Solutions to Race Conditions
| Solution | How It Works | Pros | Cons | Best For |
|---|---|---|---|---|
| Pessimistic Lock SELECT FOR UPDATE |
Lock the row before read. Other transactions wait. | Simple, guaranteed safe | Blocks other users (contention). Deadlock possible. | Low-contention resources (single-item checkout) |
| Optimistic Lock Version column |
Read with version. Write WHERE version=N. Retry if version changed. | No blocking. High throughput for low-contention workloads. | Retries under high contention. | Most CRUD operations (profile updates, settings) |
| Distributed Lock Redis SETNX |
Acquire lock on external service. Only one holder at a time. | Works across multiple services and databases. | Extra infrastructure. Lock holder crash risks. | Cross-service coordination (payment + inventory) |
| Atomic Operation DB-level CAS |
UPDATE SET qty = qty - 1 WHERE qty > 0 |
No lock needed. DB handles atomically. Fastest. | Limited to simple operations (increment/decrement). | Inventory, counters, balance deductions |
For counters and inventory, use atomic SQL: UPDATE products SET inventory = inventory - 1 WHERE id = 42 AND inventory > 0. If affected_rows = 0, the item is out of stock. This avoids locks entirely.
For complex multi-step operations (charge payment AND reserve inventory), use a distributed lock or database transaction with SELECT FOR UPDATE.
Concept 3
Distributed Locks
A distributed lock ensures that only one process across multiple machines can execute a critical section at a time. Unlike a database row lock (which works within one database), a distributed lock coordinates across services, databases, and even data centers. The most common implementation uses Redis SETNX (SET if Not eXists) with a TTL (auto-expiry).
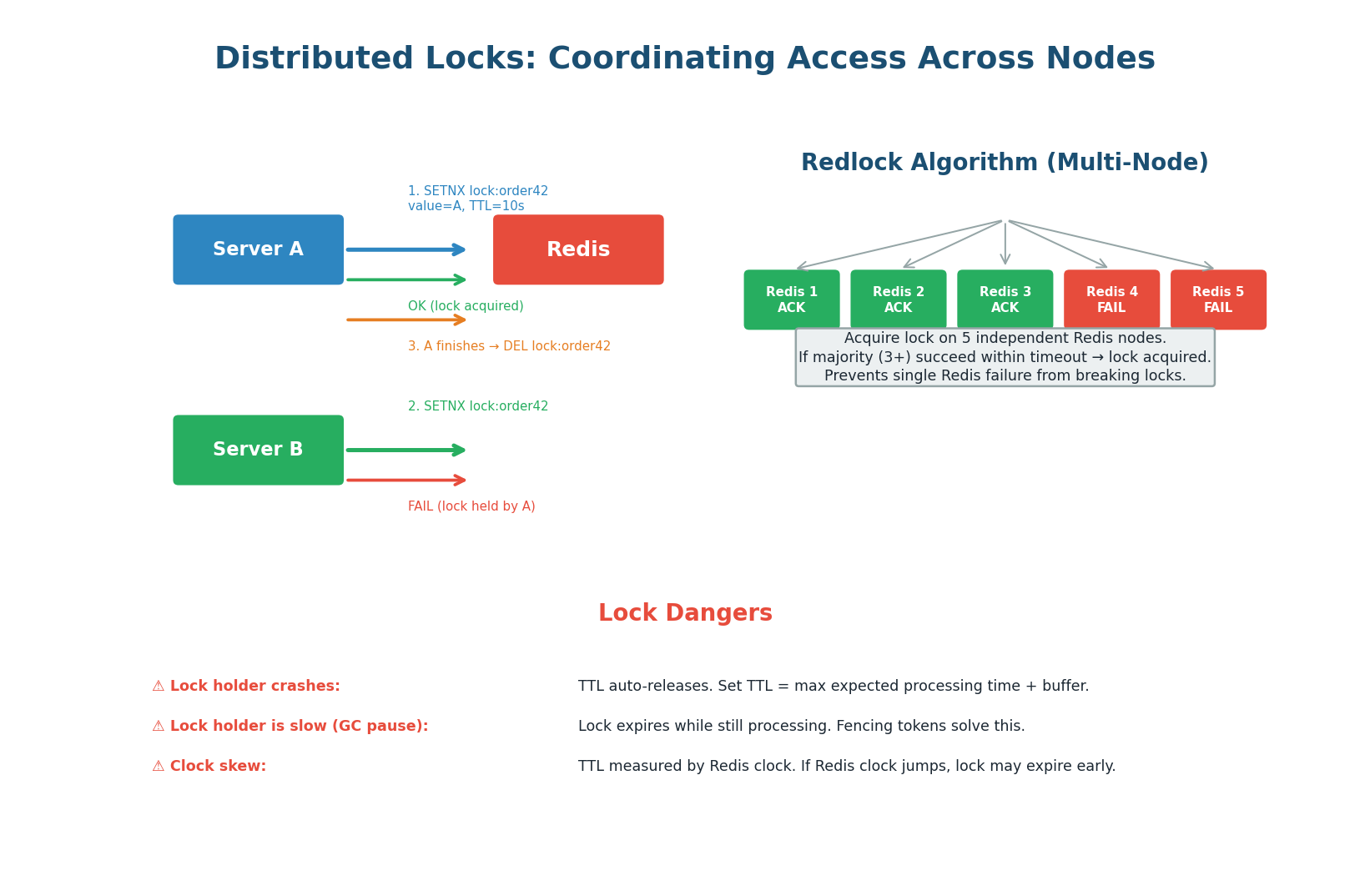
The Simple Implementation
- Acquire:
SET lock:order42 server_a_id NX EX 10(set only if not exists, expire in 10 seconds) - If
OK: lock acquired. Proceed with critical section. - If
FAIL: lock held by another server. Wait and retry, or return error. - Release:
DEL lock:order42(only if the value matchesserver_a_idto prevent releasing someone else's lock) - Safety net: TTL auto-releases if the holder crashes (no manual cleanup needed)
Multi-Node Safety
A single Redis instance is a single point of failure. Redlock solves this by acquiring the lock on 5 independent Redis instances. If the lock is acquired on a majority (3+) within a time threshold, it is considered held. This survives the failure of up to 2 Redis nodes.
Martin Kleppmann argued that Redlock is not safe under all conditions (clock drift, GC pauses). For truly critical operations, use etcd or ZooKeeper which implement consensus-based locks with stronger guarantees.
Fencing Tokens: The Extra Safety Layer

The biggest danger with distributed locks is the process pause problem. Server A acquires lock (token=33), then pauses for a long GC pause. The lock TTL expires. Server B acquires the lock (token=34) and writes to the database. Server A resumes and writes to the database, overwriting B's data — even though A no longer holds the lock.
Fencing tokens solve this: each lock acquisition returns a monotonically increasing token. The storage system rejects any write with a token lower than the highest it has seen. Server A's write with token=33 is rejected because the database already saw token=34.
A distributed lock with TTL provides at-most-once semantics within the TTL window, not true mutual exclusion. If the lock holder is slow (GC, network), the lock expires and another process acquires it — two processes are in the critical section simultaneously. Fencing tokens are the only way to make distributed locks truly safe. Without fencing, use locks only for efficiency (avoiding duplicate work), not for correctness.
"I use Redis SETNX with a 10-second TTL. The lock key is lock:order:{order_id}. The value is the server instance ID for safe release. I also use fencing tokens: the lock service returns a monotonically increasing token, and the database rejects writes with stale tokens. For critical financial operations, I use etcd's lock API which is consensus-backed and safer than Redis."
Concept 4
Leader Election
Many distributed systems require one node to act as the leader: the database primary that accepts writes, the Kafka controller that manages partition assignments, or the scheduler that assigns tasks to workers. Leader election is the process of choosing this node and handling failover when the leader dies.
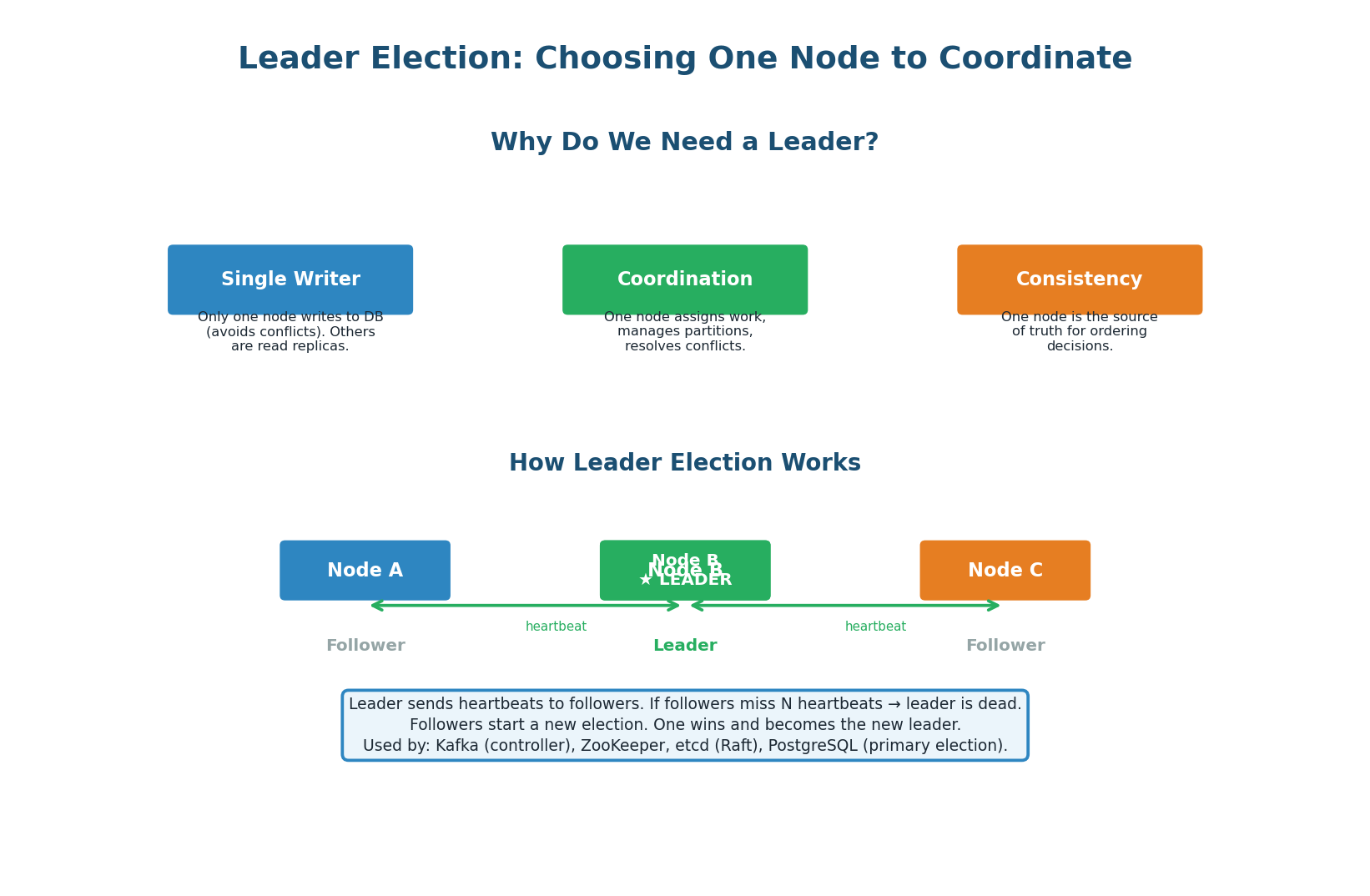
The Election Process
- Nodes start as followers. They listen for heartbeats from the current leader.
- If a follower does not receive a heartbeat within a timeout (e.g., 300ms), it assumes the leader is dead.
- The follower becomes a candidate and requests votes from other nodes.
- If the candidate receives votes from a majority (N/2+1), it becomes the new leader.
- The new leader starts sending heartbeats to all followers, preventing further elections.
- If two candidates start elections simultaneously, the one with the higher term number (epoch) wins. The other steps down to follower.
The Most Dangerous Failure Mode
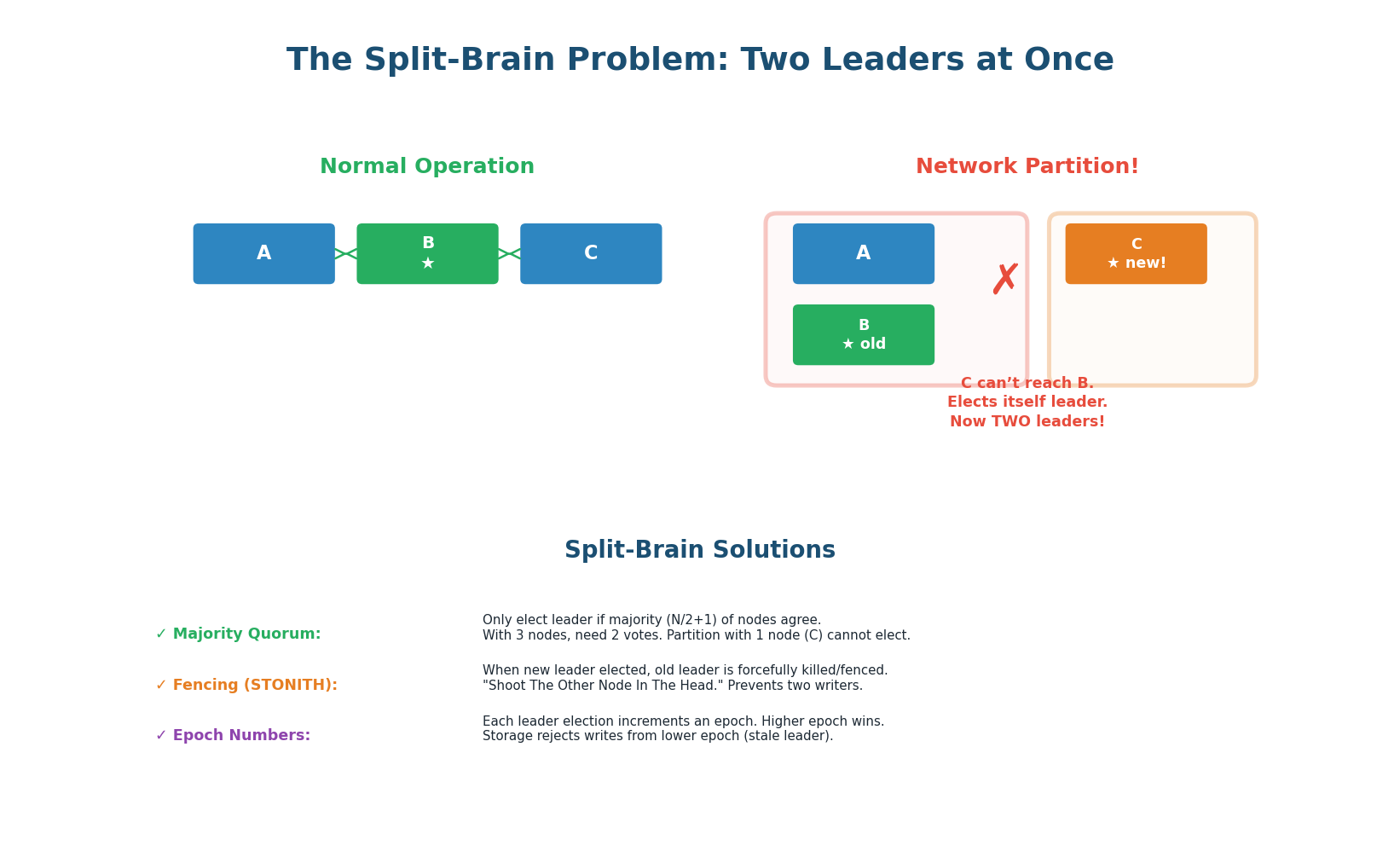
Split brain: a network partition divides the cluster into two groups, and each group elects its own leader. Now there are two leaders accepting writes, causing data conflicts and corruption. This is not theoretical — split brain has caused data loss at GitHub (2012), AWS (2017), and many other companies.
Solution — Majority Quorum: a leader can only be elected with votes from a majority (N/2+1) of all nodes, not just the nodes it can reach. With 5 nodes, you need 3 votes. If a partition splits the cluster into groups of 3 and 2, only the group of 3 can elect a leader. The group of 2 cannot elect because it does not have 3 votes. This guarantees at most one leader at any time.
| Cluster Size | Majority Required | Tolerates Failures | Common Use |
|---|---|---|---|
| 3 nodes | 2 | 1 node failure | etcd, ZooKeeper, small Kafka |
| 5 nodes | 3 | 2 node failures | Production etcd, ZooKeeper |
| 7 nodes | 4 | 3 node failures | High-availability critical systems |
4 nodes requires 3 for majority = tolerates 1 failure. 3 nodes also requires 2 for majority = also tolerates 1 failure. The 4th node adds cost and complexity without improving fault tolerance. Always use 3, 5, or 7 nodes. 5 is the production standard for etcd and ZooKeeper.
Concept 5
Consensus: How Nodes Agree
Consensus is the fundamental problem in distributed systems: how do N nodes agree on a single value (or sequence of values), even when some nodes crash or messages are lost? Leader election is a special case of consensus (agree on who the leader is). Log replication is another case (agree on the order of writes).
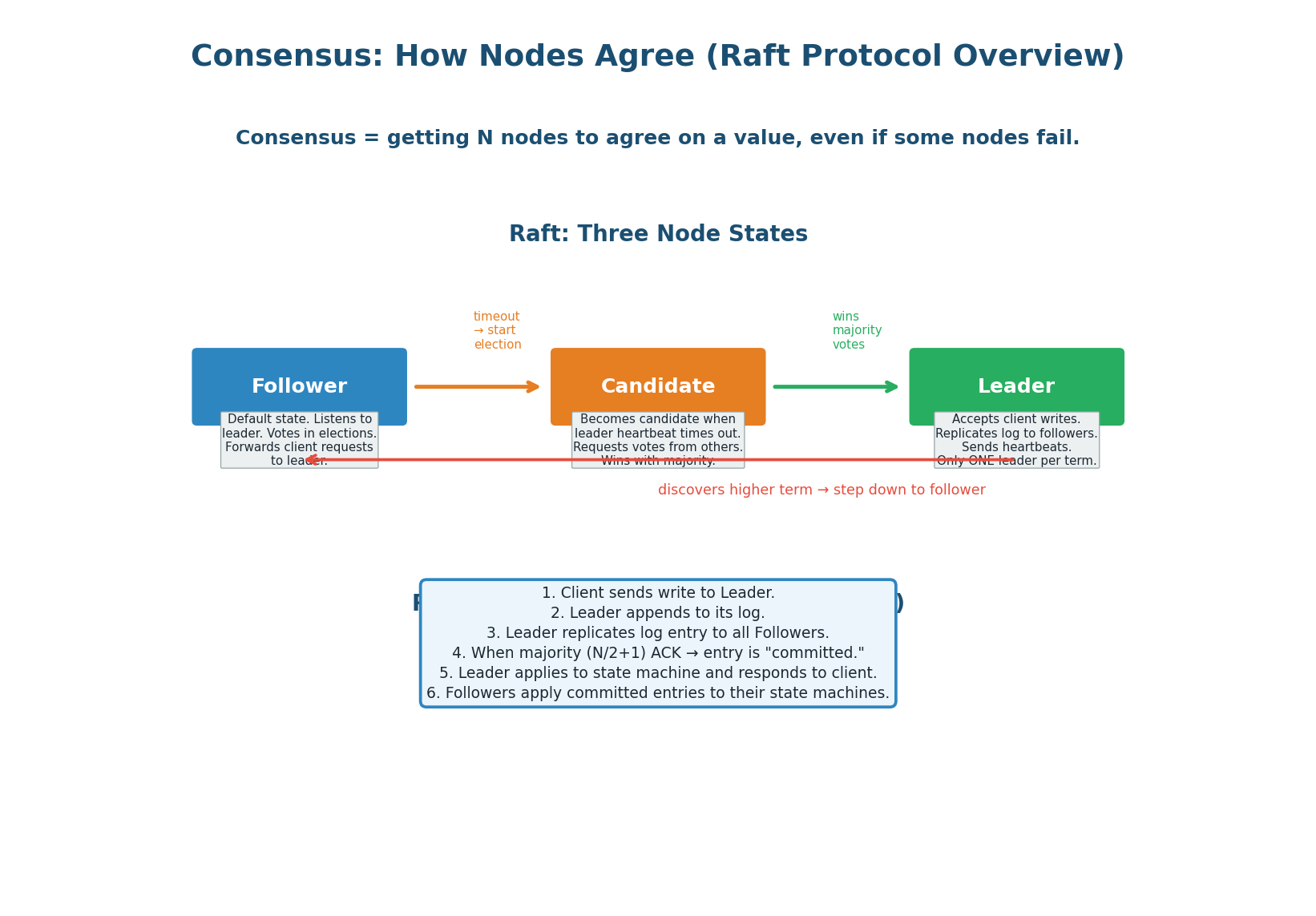
The Understandable Consensus Algorithm
Raft was designed by Diego Ongaro at Stanford specifically to be understandable (unlike Paxos, which is notoriously difficult). Raft decomposes consensus into three sub-problems: leader election (choose one leader via majority vote), log replication (leader replicates its log to followers), and safety (only a node with the most complete log can become leader).
Raft is used by etcd, CockroachDB, TiKV, and Consul.
How Writes Work in Raft
- Client sends a write request to the Leader.
- Leader appends the write to its local log as an uncommitted entry.
- Leader sends the log entry to all Followers via
AppendEntriesRPC. - Each Follower appends to its log and ACKs the Leader.
- When a majority (N/2+1) of nodes have the entry, it is committed.
- Leader applies the committed entry to its state machine and responds to the client.
- Followers learn about the commit in the next heartbeat and apply to their state machines.
A write is committed only when a majority of nodes have it. This means even if the leader crashes immediately after responding to the client, the committed entry exists on a majority of nodes and will survive. The new leader (elected from the majority) will have the entry — no data is lost.
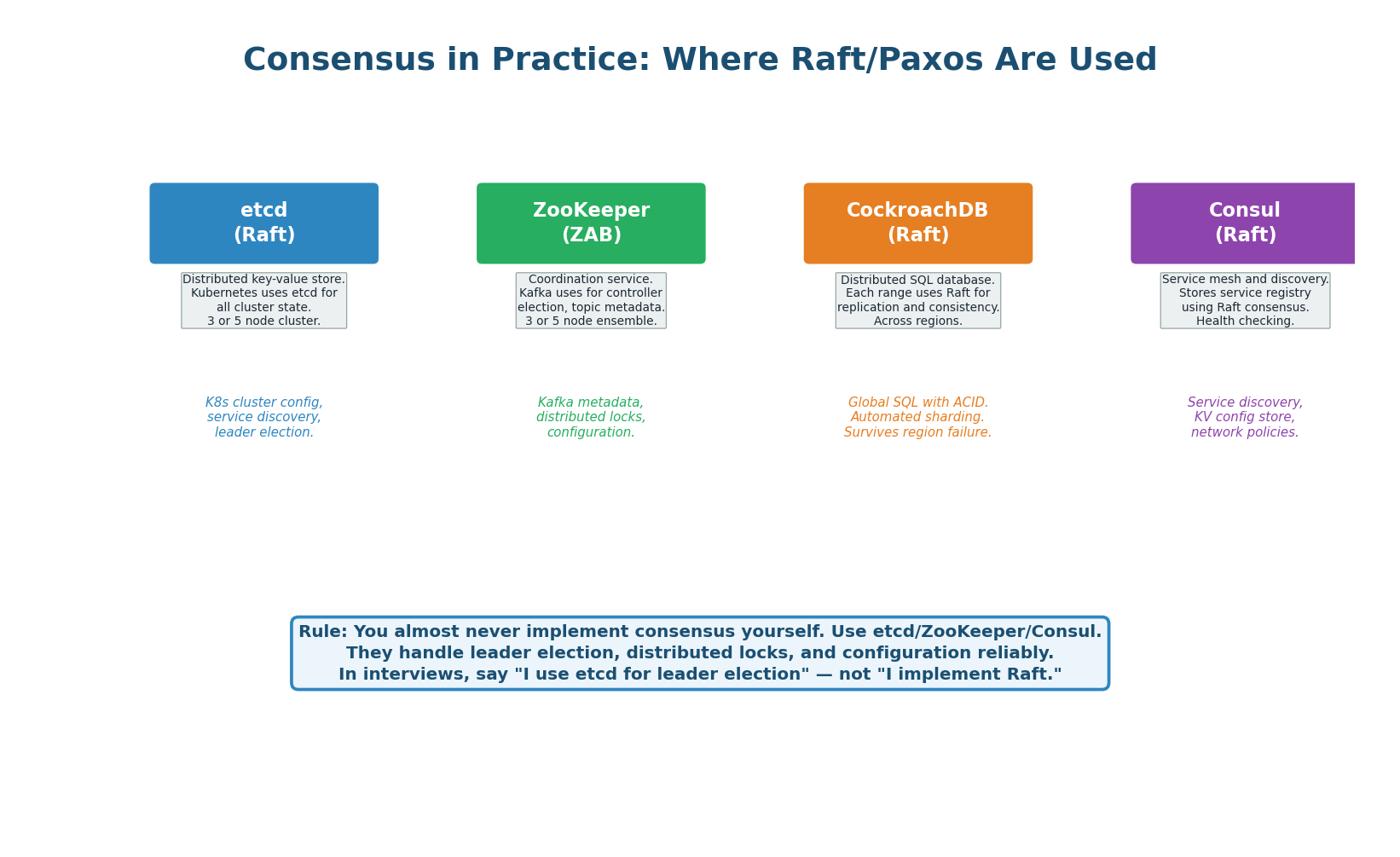
| System | Protocol | Primary Use | Cluster Size | Used By |
|---|---|---|---|---|
| etcd | Raft | Distributed KV store, K8s state | 3 or 5 | Kubernetes, CoreDNS |
| ZooKeeper | ZAB (Paxos-like) | Coordination, Kafka metadata | 3 or 5 | Kafka, Hadoop, HBase |
| CockroachDB | Raft (per range) | Distributed SQL database | 3+ per range | DoorDash, Netflix |
| Consul | Raft | Service discovery, KV config | 3 or 5 | HashiCorp ecosystem |
| Google Spanner | Paxos + TrueTime | Global SQL, external consistency | 5+ per split | Google internally |
"For leader election, I use etcd's election API (backed by Raft consensus). For distributed configuration, I use etcd's KV store. I do NOT implement Raft myself — consensus algorithms are notoriously hard to get right, and battle-tested implementations like etcd and ZooKeeper handle all edge cases." This shows you know when to build vs when to use existing tools.
Concept 6
Consistency Models & Decision Guide
Consistency models define what a client can observe when reading data that is being written concurrently by others. Stronger consistency means clients always see the latest data, but it is slower (every read must check with the majority). Weaker consistency means clients may see stale data, but reads are faster (any replica can respond).
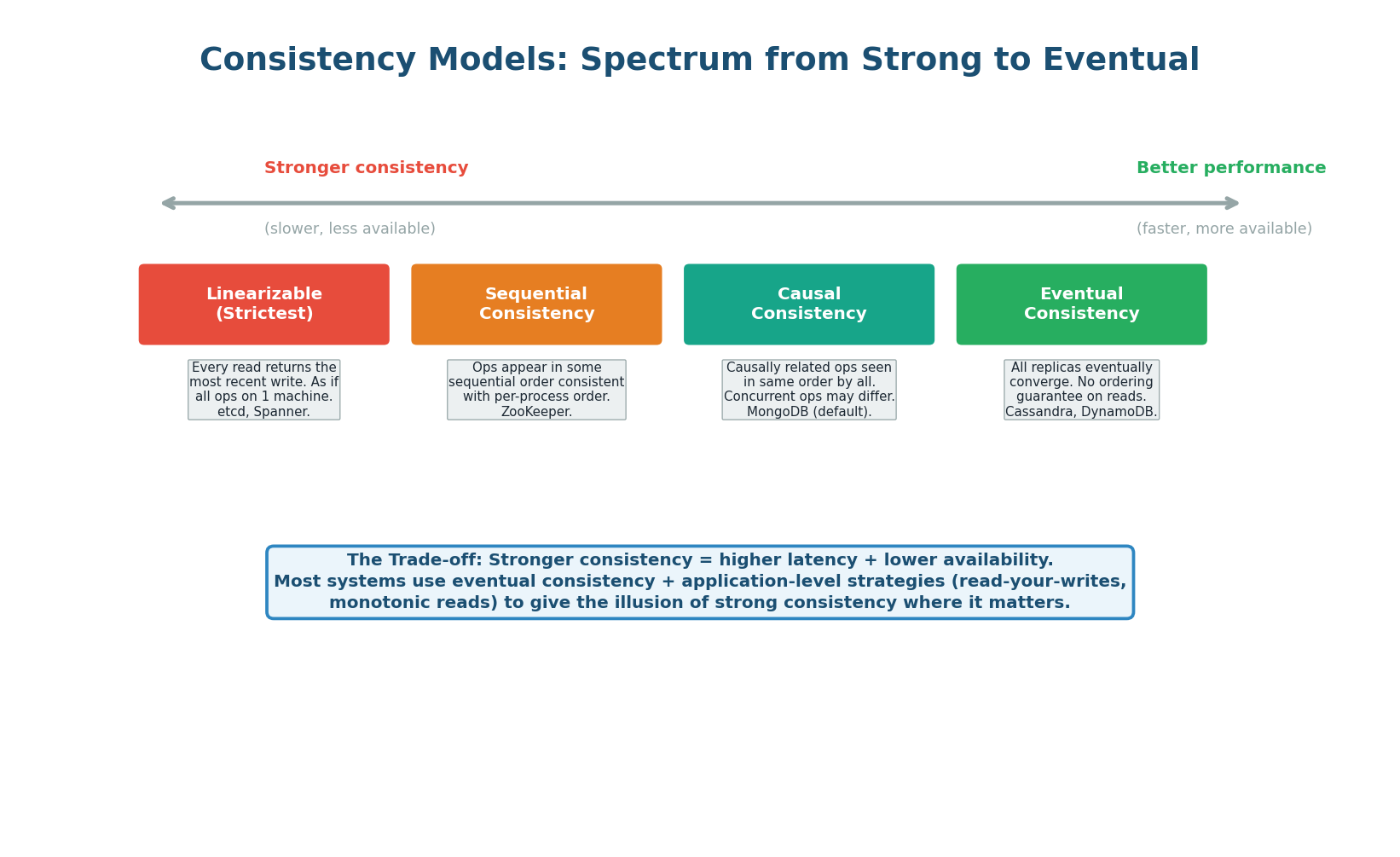
| Model | Guarantee | Latency | Use Case |
|---|---|---|---|
| Linearizable | Every read sees the most recent write. Strictest. | High (quorum read) | Banking, leader election, locks |
| Sequential | All nodes see operations in the same order. | Medium | ZooKeeper, ordered logs |
| Causal | Causally related operations are ordered; concurrent may differ. | Lower | Social feeds (see your own posts immediately) |
| Eventual | All replicas converge eventually. No ordering guarantee. | Lowest | Cassandra, DynamoDB, DNS, CDN |
Most production systems use eventual consistency for the majority of operations (reads from replicas, cache-aside pattern) and strong consistency only where it matters (financial transactions, inventory, leader election). Application-level strategies like read-your-writes (route the user's own reads to the primary) give the illusion of strong consistency for the most important use case — the user seeing their own recent changes — without the performance cost of making every read linearizable.
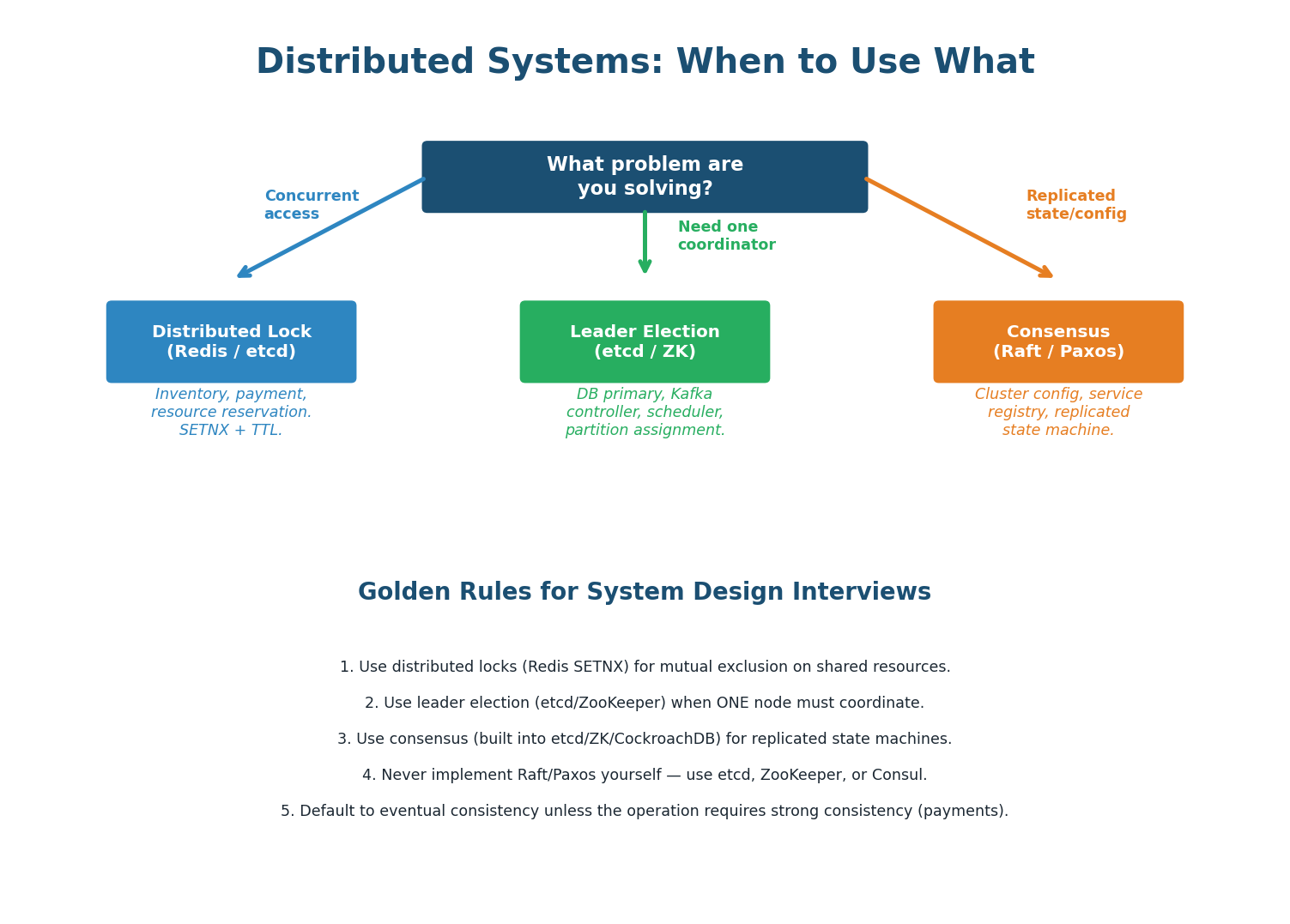
| Problem | Solution | Tool | Example |
|---|---|---|---|
| Prevent two users buying the last item | Distributed Lock | Redis SETNX / etcd lock | E-commerce inventory |
| Choose one DB primary to accept writes | Leader Election | etcd / ZooKeeper | PostgreSQL failover |
| All nodes agree on the order of writes | Consensus (Raft) | etcd / CockroachDB | Replicated state machine |
| One scheduler assigns tasks to workers | Leader Election | etcd / ZooKeeper | Job scheduler, Kafka controller |
| Store cluster configuration reliably | Consensus KV store | etcd / Consul | Kubernetes cluster state |
| Prevent split-brain after network partition | Majority Quorum | Raft / ZAB | Any replicated system |
Pre-Class Summary
Six Concepts to Know Before Class
Why It's Hard
Unreliable networks, unsynchronized clocks, and process crashes. Every distributed algorithm exists to cope with these three demons.
Race Conditions
Lost updates happen when two operations read and write without coordination. Default to atomic SQL for counters; distributed locks for cross-service coordination.
Distributed Locks
Redis SETNX + TTL for basic locking. Redlock for multi-node safety. Fencing tokens add correctness. For critical ops, use etcd (consensus-backed).
Leader Election
Heartbeats + majority voting. Split brain prevented by N/2+1 quorum. Always use odd cluster sizes (3, 5, 7). etcd and ZooKeeper implement this.
Consensus (Raft)
Leader election + log replication + safety. Writes committed when majority ACK. Used by etcd, CockroachDB, Consul. Never implement yourself.
Consistency Models
Linearizable (strictest) → eventual (fastest). Use eventual consistency for most reads. Use strong consistency only for financial operations and locks.
Want to Land at Google, Microsoft or Apple?
Watch Pranjal Jain's free 30-min training — the exact GROW Strategy that helped 1,572+ engineers go from TCS/Infosys to top product companies with a 3–5X salary hike.