Consistency Models in Distributed Systems Deep Dive + 30-Question Quiz
Part 1: Read — master the five consistency models from Linearizability to Eventual Consistency. Part 2: Test yourself with a 30-question quiz covering all Class 2 topics.
By Pranjal Jain• Mar 6, 2026• 40 min read• 30 questions
In Class 2, we learned about the CAP theorem: in a distributed system, you must choose between Consistency and Availability during a network partition. But that raises a crucial follow-up question: what exactly do we mean by "consistency"? It turns out there is not just one kind — there is an entire spectrum, from the strictest guarantees to the loosest.
Understanding this spectrum is essential because different parts of your system need different consistency levels. A payment system that allows a user to spend money they have already spent would be catastrophic. But a social media feed that shows a post 2 seconds late? Nobody notices. Choosing the right consistency model for each feature is one of the most important architectural decisions you will make.
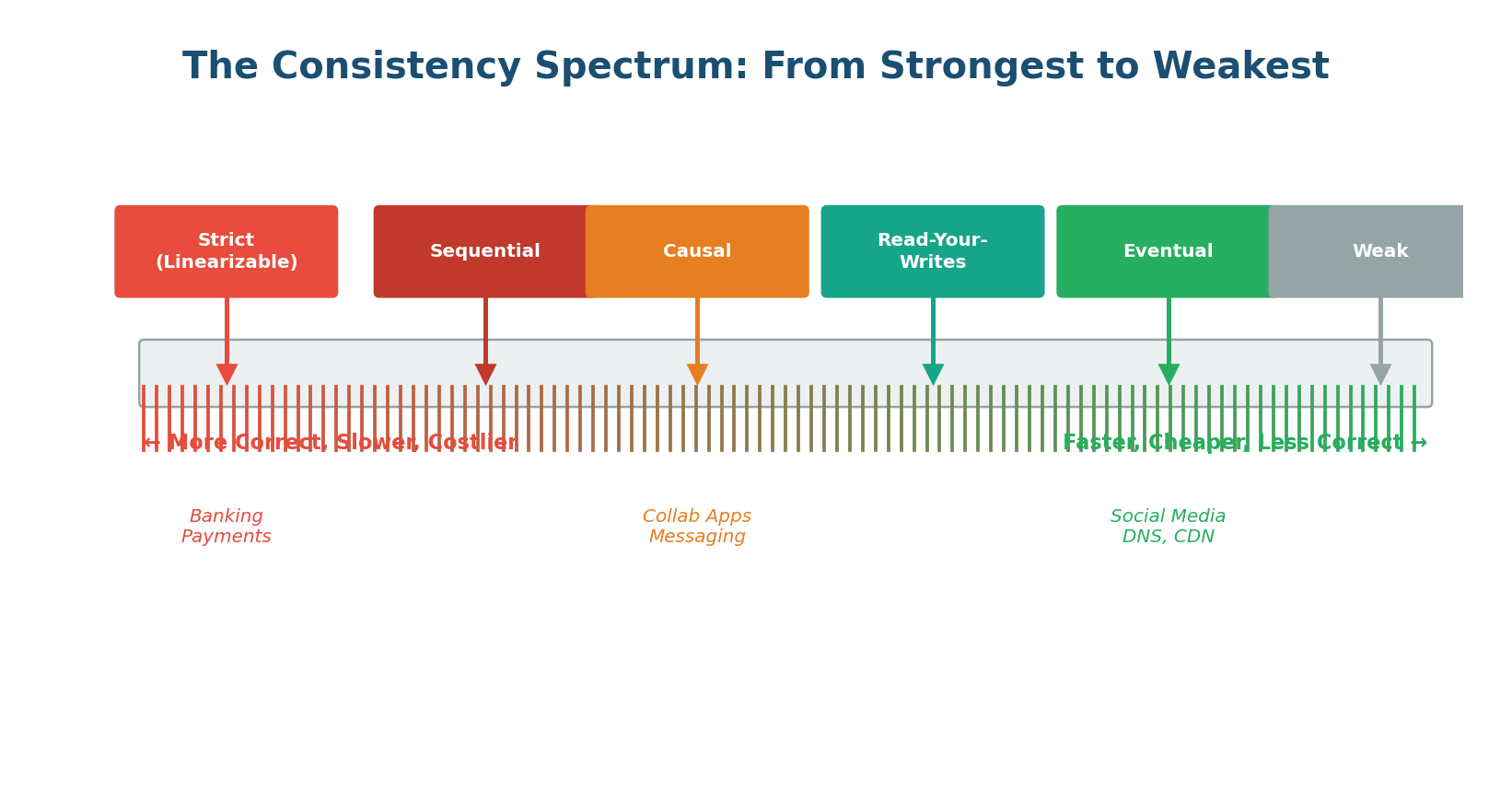
Figure 1: The Consistency Spectrum — from Linearizability (strongest) to Eventual Consistency (weakest)
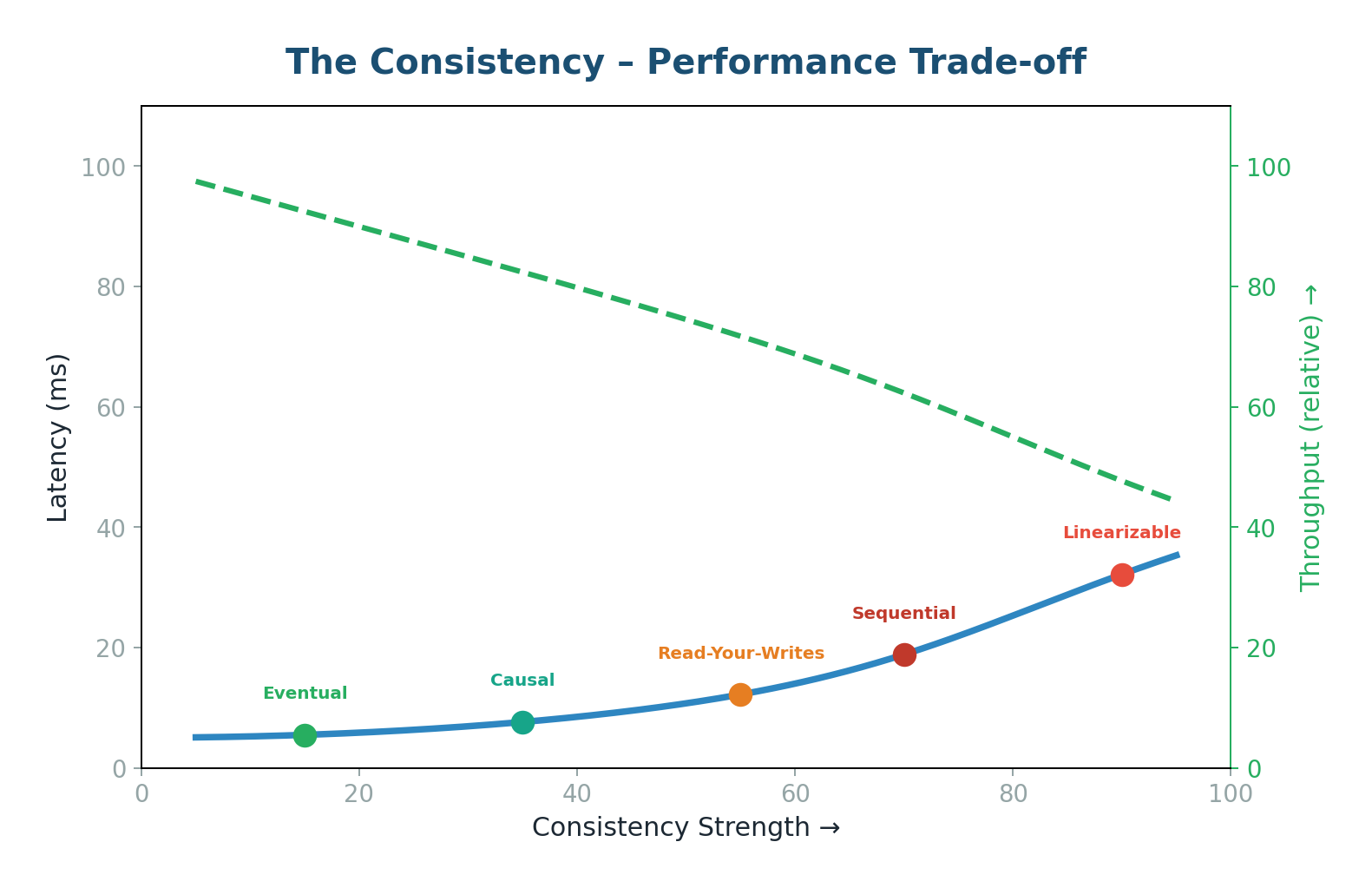
Moving from left to right on this spectrum, you trade correctness for performance. Stronger models require more coordination between nodes (adding latency and reducing availability), while weaker models allow nodes to respond independently (faster and more available but may return stale data).
MODEL 1
Linearizability (Strong Consistency)
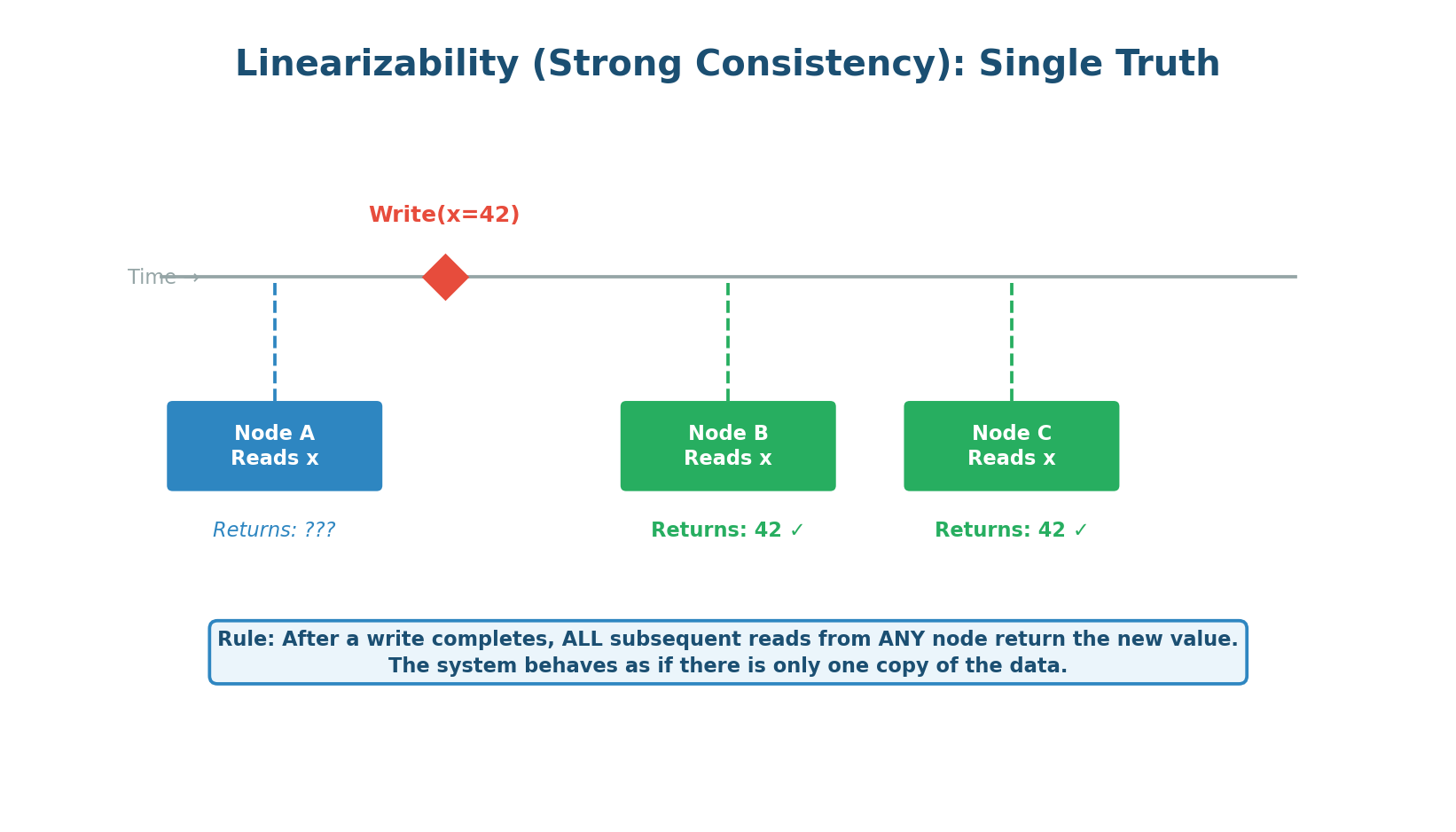
Linearizability is the gold standard of consistency. It provides the illusion that there is only one copy of the data in the entire system, and every operation is atomic — it happens instantaneously at some point between its start and completion. After a write completes, every subsequent read from any node in the system is guaranteed to return the new value.
Figure 2: Linearizability — after Write(x=42) completes, all reads from all nodes return 42
How it works: A leader node coordinates all writes. Before a write is acknowledged, the leader ensures a majority of replicas (quorum) have accepted it. Consensus protocols like Raft and Paxos implement this.
The cost: Every write requires a round-trip to a majority of nodes. This adds latency (50–200ms for cross-region writes) and reduces availability (if a majority of nodes are unreachable, the system halts).
Use When
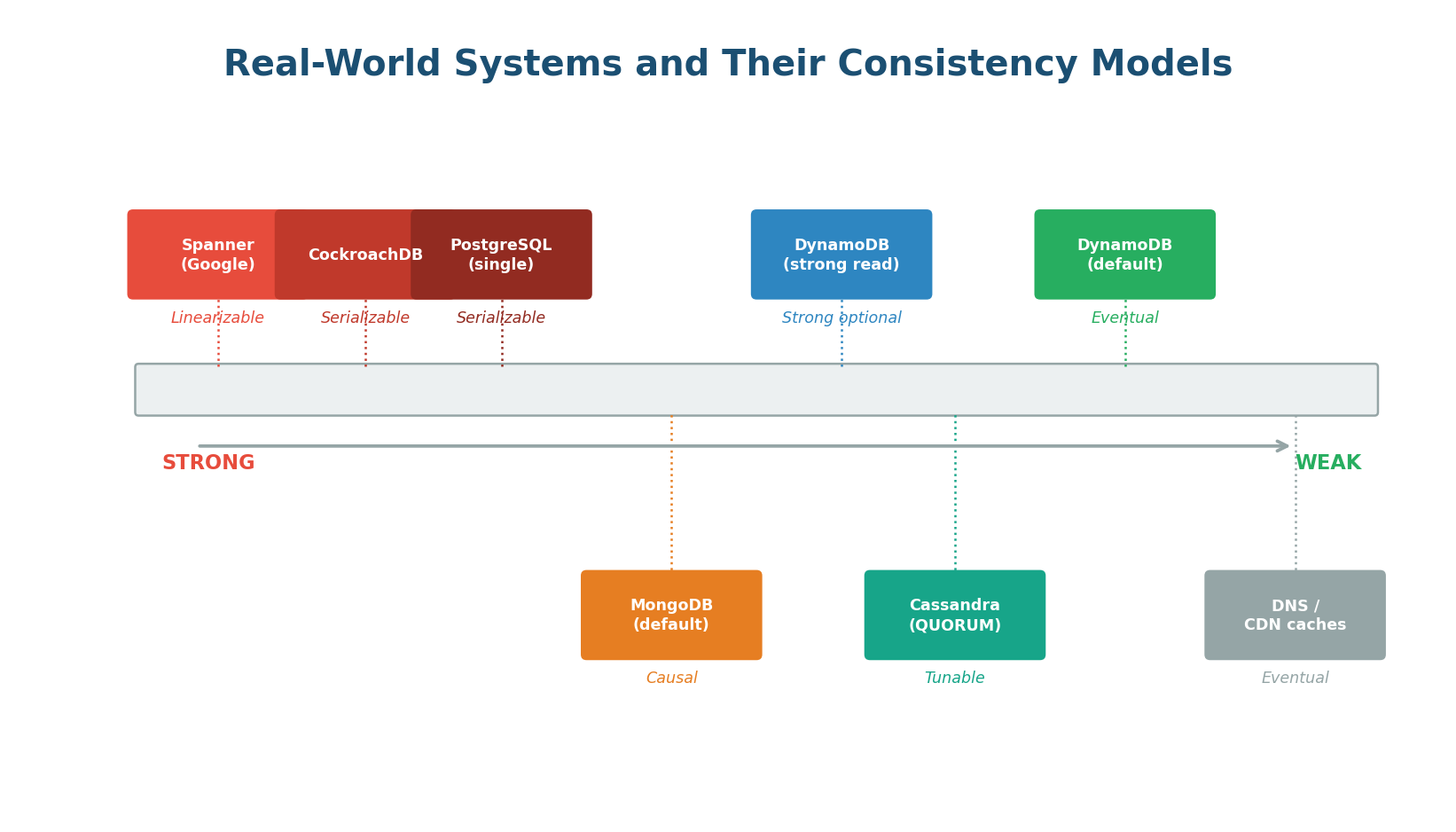
Bank account balances, inventory counts, leader election, distributed locks, payment processing. Getting the wrong answer is worse than getting no answer. Real-world examples: Google Spanner, CockroachDB, etcd, Zookeeper, PostgreSQL (single-node).
MODEL 2
Sequential Consistency
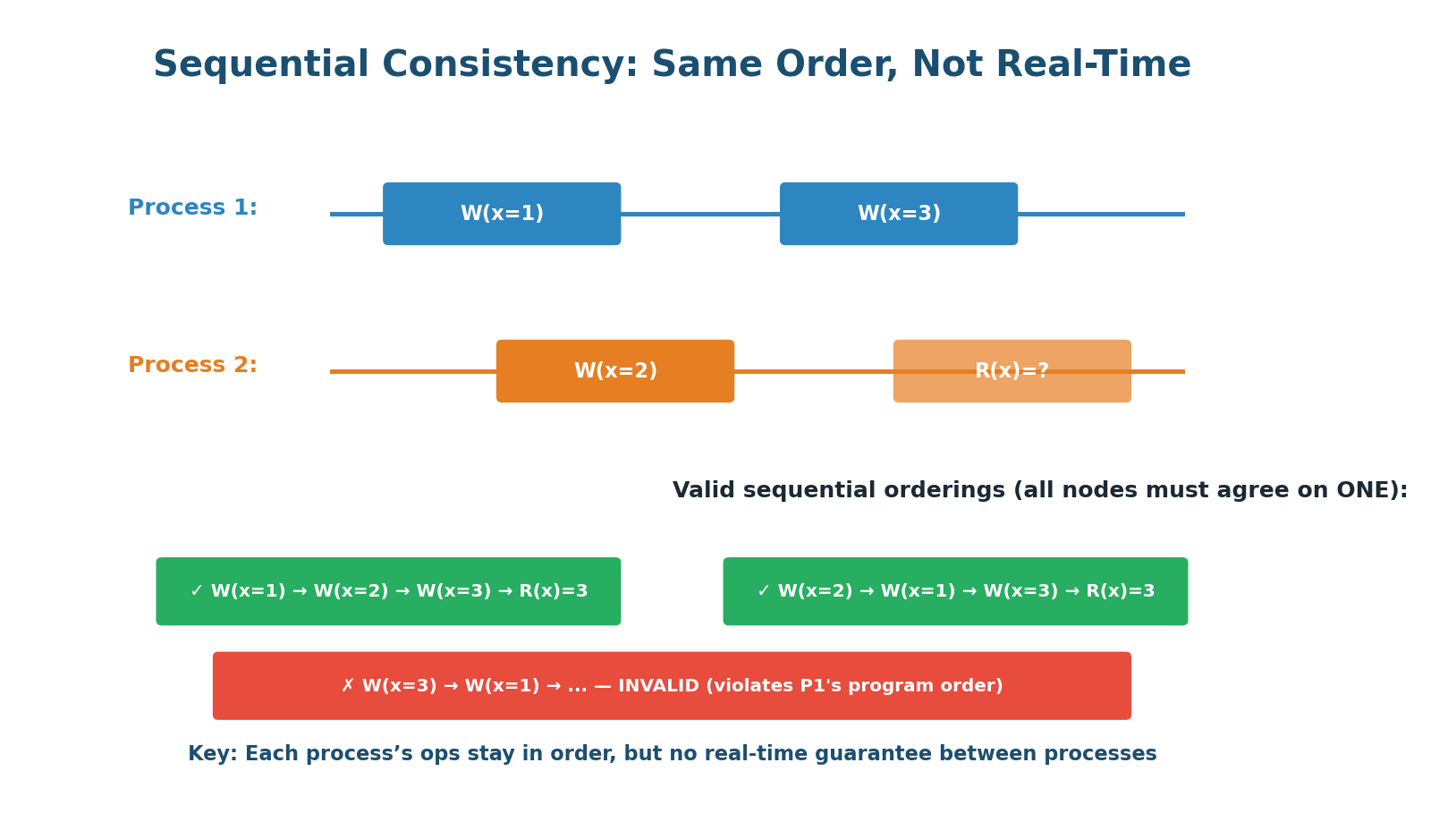
Sequential consistency is slightly weaker than linearizability. It guarantees that all clients see all operations in the same order, and operations from each individual client appear in the order that client issued them. However, it does not guarantee real-time ordering — a write at time T may not be visible to other clients until some later time.
Figure 3: Sequential Consistency — all clients see writes in the same order, but may be delayed
The critical rule: If Client 1 writes x=1 and then writes y=2, every other client must see x=1 before y=2. They can see both late, but the order must be preserved.
How it differs from linearizability: With linearizability, a write at 10:00:00 must be visible to readers at 10:00:01. With sequential consistency, the write may still be invisible at 10:00:01 — it only guarantees the order of operations is consistent, not that it matches real time.
Use When
You need a consistent view of event ordering but not real-time guarantees. Multi-player gaming (turn order matters), collaborative workspaces, event logs. Examples: ZooKeeper (for reads from followers), many multi-core CPU memory models.
MODEL 3
Causal Consistency
Causal consistency relaxes the ordering guarantee further. Instead of requiring all operations to be ordered, it only requires causally related operations to be ordered. Two operations are causally related if one could have influenced the other. Concurrent, independent operations can appear in any order.
Figure 4: Causal Consistency — Bob's reply was caused by Alice's post, so Alice must appear first
The intuition: If Alice says "Anyone free?" and Bob replies "I am!", everyone must see Alice's message before Bob's reply — the reply was caused by the question. But Dave's unrelated message "Nice weather!" can appear in any order — it was not caused by either.
How it is tracked: Vector clocks or version vectors track causal dependencies. Each operation carries metadata about which operations it "depends on."
Why It Matters
Causal consistency is the strongest model that can be achieved in an always-available system (no CP trade-off required). It gives users an intuitive experience without requiring expensive global coordination. Examples: MongoDB (causal consistency sessions), Google Docs, Figma (using CRDTs).
MODEL 4
Session Guarantees
Session guarantees are a pragmatic middle ground that makes eventual consistency much more usable. Instead of guaranteeing consistency across all clients, they guarantee consistency within a single client's session. This is often sufficient — the most jarring inconsistency for users is when they perform an action and cannot see their own change.
Figure 5: Four session guarantees — each protects a single client from seeing confusing inconsistencies
Read Your Writes (RYW): After you write a value, your subsequent reads will always return at least that value. You will never upload a profile picture and then refresh to see the old one. The most important session guarantee.
Monotonic Reads: Reads never "go backwards in time." If you read value V at time T1, reading again at T2 will return V or something newer — never something older.
Monotonic Writes: Your writes are applied in the order you issued them. Updating name to "Alice" then "Alice Smith" is always applied in that order.
Writes Follow Reads: If you read a value and then write based on it, your write is guaranteed to be applied after the read. Post a reply only after the thread exists.
MODEL 5
Eventual Consistency
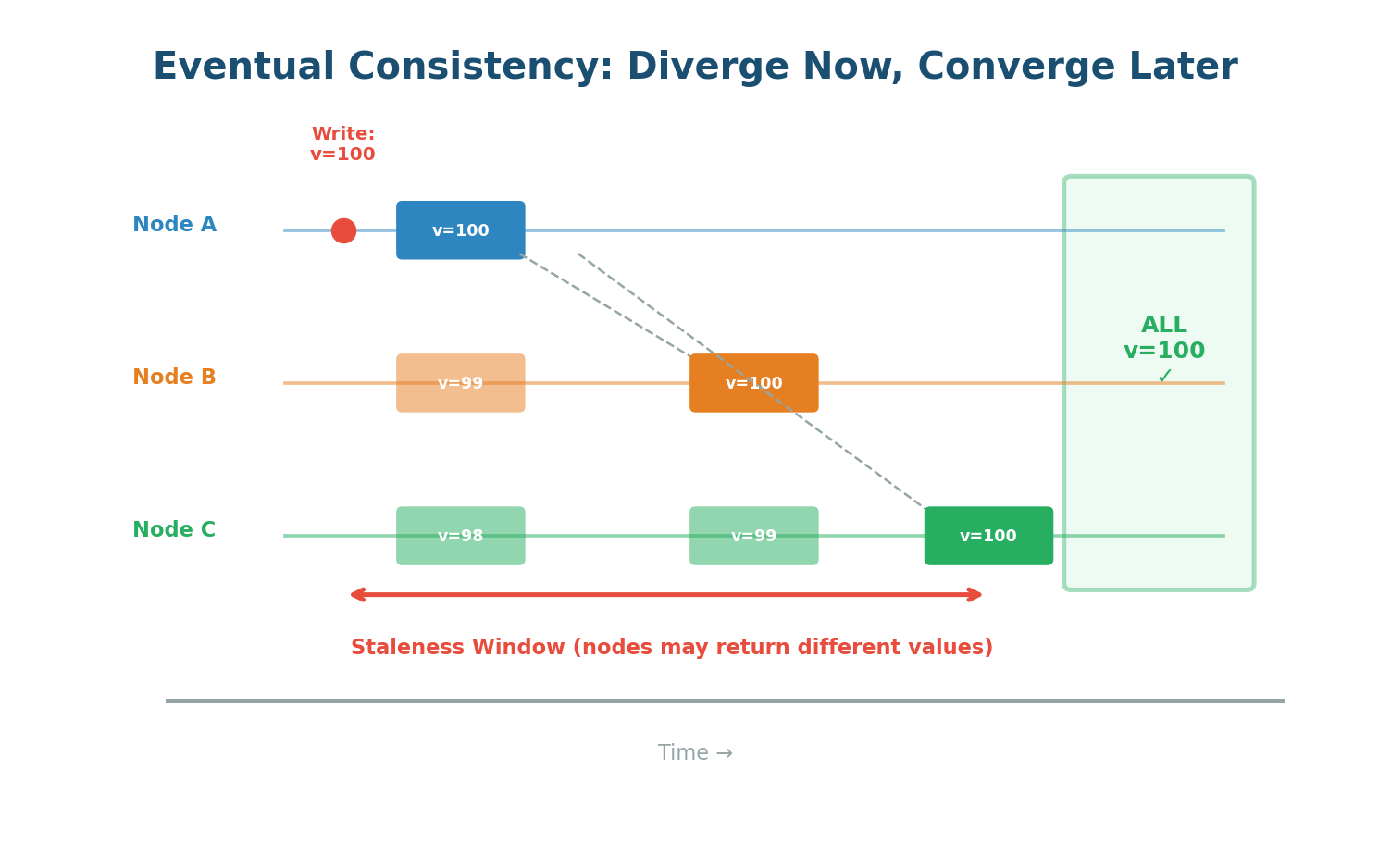
Eventual consistency is the weakest useful guarantee. It promises only that if no new updates are made, eventually all replicas will converge to the same value. During the convergence window, different nodes may return different values for the same data.
Figure 6: Eventual Consistency — after a write, nodes diverge temporarily, then converge over time
The convergence window: In Cassandra with healthy networks, typically under 100ms. In a geo-replicated DynamoDB with global tables, can be 1–2 seconds. In DNS, the TTL can mean hours of staleness.
Conflict resolution strategies: Last-Write-Wins (LWW) uses timestamps; CRDTs (Conflict-free Replicated Data Types) allow automatic conflict-free merging; Application-level resolution presents both values to the user.
Use When
Availability and low latency matter more than immediate consistency. Social media feeds, DNS, CDN caches, shopping carts, session data, analytics. Examples: Cassandra, DynamoDB, CouchDB, Riak, Route 53, Cloudflare CDN.
Choosing
Mapping Use Cases to Models
Figure 7: Real-world systems mapped to their consistency models
Consistency Model
Latency
Availability
Best Use Cases
Linearizability
High (100–200ms)
Lower (blocks on partition)
Payments, inventory, locks
Sequential
Medium-High
Medium
Gaming, event logs
Causal
Medium
High (always available)
Messaging, docs, social
Session
Low-Medium
High
User profiles, e-commerce
Eventual
Very Low
Highest
DNS, CDN, analytics, feeds
ADVANCED
Tunable Consistency: The Best of Both Worlds
Figure 8: Tunable Consistency in Cassandra — adjust Write and Read quorum per query
Modern databases like Cassandra and DynamoDB offer tunable consistency — you choose the consistency level per query. The magic formula: if W + R > N (where W = write quorum, R = read quorum, N = replication factor), you get strong consistency.
With N=3: QUORUM writes (W=2) + QUORUM reads (R=2) = 4 > 3, so you always read the latest write. ONE/ONE = 1+1=2, which is NOT > 3, so you may read stale data — but it is much faster and more available.
Figure 9: Trade-offs at a glance — no model is universally best
Part 2
Core Concepts Quiz — 30 Questions
Challenge
Test your understanding of all Class 2 concepts: Scalability, Availability, Reliability, SPOF, Latency/Throughput/Bandwidth, Consistent Hashing, CAP Theorem, and Consistency Models. Target: 24+ correct (80%+). Click "Show Answer" after attempting each question.
Class 2 Core Concepts Quiz — 30 questions covering all topics
Section A: Scalability & Performance (Q1–Q8)
Q1
What is the primary difference between vertical and horizontal scaling?
A) Vertical scaling adds more machines; horizontal scaling adds more power to one machine
B) Vertical scaling adds more power to one machine; horizontal scaling adds more machines
C) Vertical scaling is always cheaper than horizontal scaling
D) There is no practical difference; both achieve the same result
Answer: B
Vertical scaling means making one machine more powerful (more CPU, RAM). Horizontal scaling means adding more machines behind a load balancer.
Q2
Which of the following is NOT a common scalability strategy?
A) Database sharding
B) Caching with Redis
C) Synchronous blocking of all requests
D) Load balancing
Answer: C
Synchronous blocking of all requests is an anti-pattern that destroys throughput. Sharding, caching, and load balancing are proven scalability strategies.
Q3
What does p99 latency mean?
A) 99% of requests complete faster than this time
B) The average response time for 99 requests
C) The fastest 99% of all responses
D) 99% of the time the system is available
Answer: A
p99 latency is the value below which 99% of requests complete. It captures the worst-case experience for most users and is critical for SLA monitoring.
Q4
If a server handles 10,000 RPS and you need to support 80,000 RPS with 2× redundancy, how many servers do you need?
A) 8
B) 16
C) 10
D) 80
Answer: B
80,000 / 10,000 = 8 servers for capacity. With 2× redundancy, 8 × 2 = 16 servers. This ensures the system can lose half its servers and still handle peak load.
Q5
What happens to latency as throughput approaches maximum capacity?
A) Latency decreases linearly
B) Latency stays constant
C) Latency increases exponentially (hockey stick curve)
D) Latency becomes unpredictable but stays low
Answer: C
As throughput approaches capacity, queues form and latency increases exponentially (the hockey stick curve). This is why production systems target 70–80% utilization.
Q6
Approximately how much faster is reading from RAM compared to SSD random read?
A) 10×
B) 100×
C) 1,000×
D) They are approximately the same speed
Answer: C
RAM access is ~100ns; SSD random read is ~100µs. That is 100,000ns vs 100ns = approximately 1,000× faster. This is why caching hot data in memory is so impactful.
Q7
What is the difference between bandwidth and throughput?
A) They are the same thing
B) Bandwidth is the maximum capacity; throughput is the actual usage
C) Throughput is always higher than bandwidth
D) Bandwidth measures latency; throughput measures data volume
Answer: B
Bandwidth is the maximum capacity of the pipe (highway lanes). Throughput is how much actually flows through (actual cars on the road). Throughput ≤ Bandwidth always.
Q8
A CDN primarily improves performance by:
A) Increasing the server's CPU speed
B) Serving content from edge servers closer to users, reducing network latency
C) Compressing all data to 10% of original size
D) Caching database queries in RAM
Answer: B
CDNs place content on edge servers geographically close to users, reducing network latency from potentially hundreds of milliseconds to single-digit milliseconds.
Section B: Availability & Reliability (Q9–Q14)
Q9
A system with 99.99% availability can have at most how much annual downtime?
What is the key difference between reliability and availability?
A) They are the same concept with different names
B) Availability means the system is up; reliability means it produces correct results
C) Reliability is about hardware; availability is about software
D) Availability is more important than reliability
Answer: B
Availability = is the system up and responding? Reliability = are the responses correct? A system can be up (available) but return wrong data (unreliable).
Q11
A system that is available but unreliable is:
A) Perfect for production use
B) Dangerous — it is up but may return wrong data without users knowing
C) Impossible — availability implies reliability
D) Acceptable for all use cases
Answer: B
An available but unreliable system is dangerous because users trust the responses. Returning incorrect data (e.g., wrong bank balance) can be worse than downtime.
Q12
What does a circuit breaker pattern do?
A) Cuts electricity to the server to prevent overheating
B) Stops calling a failing downstream service to prevent cascading failures
C) Encrypts data to prevent circuit attacks
D) Balances load across servers
Answer: B
A circuit breaker detects a failing service (after repeated failures), stops calling it temporarily, and periodically tests if it has recovered. This prevents cascading failures.
Q13
Which strategy protects against an entire data center going offline?
A) Vertical scaling
B) Adding more RAM to each server
C) Multi-region deployment with cross-region replication
D) Using a faster programming language
Answer: C
Multi-region deployment ensures that if an entire data center or region goes offline, traffic can be routed to another region.
Q14
What is a Single Point of Failure (SPOF)?
A) A server that handles the most traffic
B) A component whose failure would cause the entire system to stop working
C) A backup server that never gets used
D) A server with only one network connection
Answer: B
A SPOF is any component with no backup whose failure takes down the entire system. Examples: single load balancer, single database, single DNS server.
Section C: Consistent Hashing (Q15–Q20)
Q15
What is the main problem with using Hash(key) mod N for distributing data across N servers?
A) The hash function is too slow
B) When N changes, most keys must be redistributed
C) It only works with 3 or fewer servers
D) It requires all servers to be identical
Answer: B
With Hash(key) mod N, changing N causes most keys to map to different servers. For 10 servers, adding 1 server reshuffles ~91% of keys, causing massive cache invalidation.
Q16
In consistent hashing, when you add one server to a ring with N servers, approximately what fraction of keys need to move?
A) All keys (100%)
B) (N-1)/N of all keys
C) 1/N of all keys
D) No keys need to move
Answer: C
With consistent hashing, adding one server to N servers only moves ~1/N of all keys. With 10 servers, that is ~10% — compared to ~91% with modular hashing.
Q17
What problem do virtual nodes (VNodes) solve?
A) They increase the hash ring size
B) They ensure even distribution of keys when physical servers cluster on the ring
C) They encrypt data on the ring
D) They reduce the number of servers needed
Answer: B
With few physical servers, random hash positions can cluster together, causing uneven key distribution. Virtual nodes give each server multiple positions on the ring for even spread.
Q18
In consistent hashing, how is a key assigned to a server?
A) The key is assigned to the server with the lowest ID
B) The key's hash position is found on the ring, then the next server clockwise owns it
C) A random server is chosen for each key
D) The key is assigned using Hash(key) mod N
Answer: B
Both keys and servers are hashed onto a ring. A key belongs to the first server found by traversing clockwise from the key's position on the ring.
Q19
Which of these systems does NOT use consistent hashing?
A) Apache Cassandra
B) Amazon DynamoDB
C) A single PostgreSQL instance
D) Discord message routing
Answer: C
A single PostgreSQL instance is not a distributed system and does not need consistent hashing. Cassandra, DynamoDB, and Discord all use consistent hashing to distribute data.
Q20
If Server B on a consistent hash ring fails, what happens to its keys?
A) All keys in the system are redistributed
B) Only Server B's keys move to the next server clockwise on the ring
C) The system crashes until Server B is restored
D) Keys are randomly reassigned to all remaining servers
Answer: B
Only the keys assigned to Server B need to move. They are reassigned to the next server clockwise. All other keys remain with their current servers — minimal disruption.
Section D: CAP Theorem & Consistency Models (Q21–Q30)
Q21
What does the CAP theorem state?
A) Distributed systems can have Consistency, Availability, and Partition tolerance simultaneously
B) In the presence of a network partition, you must choose between Consistency and Availability
C) Partition tolerance is optional in distributed systems
D) Consistency and Availability are the same thing
Answer: B
CAP states: in a distributed system, during a network partition, you must choose between Consistency and Availability. Since partitions are inevitable, the real choice is CP or AP.
Q22
A CP system during a network partition will:
A) Return stale data to maintain availability
B) Return errors or become unavailable rather than serve potentially inconsistent data
C) Continue operating with no impact
D) Automatically switch to eventual consistency
Answer: B
CP systems sacrifice availability for consistency. During a partition, they return errors or become unavailable rather than risk serving stale or inconsistent data.
Q23
Which is an example of an AP system?
A) Zookeeper
B) A single PostgreSQL instance
C) Cassandra
D) etcd
Answer: C
Cassandra is AP: it prioritizes availability, serving requests from any available node even during partitions, accepting eventual consistency. Zookeeper and etcd are CP.
Q24
Linearizability guarantees that:
A) All writes are eventually visible
B) Operations from the same client are ordered
C) After a write completes, all subsequent reads from any node return the new value
D) Writes are applied in causal order only
Answer: C
Linearizability guarantees that once a write completes, all subsequent reads from any node return the new value. It provides the strongest possible consistency guarantee.
Q25
What is the key difference between sequential consistency and linearizability?
A) Sequential consistency does not guarantee real-time ordering of operations
B) Sequential consistency is stronger than linearizability
C) They are identical
D) Sequential consistency does not order operations at all
Answer: A
Both guarantee all clients see operations in the same order, but linearizability additionally requires operations to respect real-time ordering. Sequential consistency allows a delay.
Q26
In a social media app, Alice posts a photo and immediately refreshes. With Read-Your-Writes consistency, she will:
A) Always see the old page without her photo
B) Always see her own photo, even if others haven't seen it yet
C) See the photo only 50% of the time
D) Need to wait 5 minutes before refreshing
Answer: B
Read-Your-Writes guarantees that after you perform a write, your own subsequent reads always reflect that write. Alice will always see her own photo immediately.
Q27
Causal consistency requires that:
A) All operations are globally ordered
B) Operations with a cause-and-effect relationship are seen in the correct order
C) All reads return the latest value
D) No two operations can happen concurrently
Answer: B
Causal consistency only orders operations that have a cause-and-effect relationship. Concurrent, independent operations can appear in any order on different nodes.
Q28
In Cassandra with replication factor 3, which configuration gives strong consistency?
A) Write: ONE, Read: ONE
B) Write: QUORUM (2), Read: QUORUM (2)
C) Write: ONE, Read: ALL
D) Both B and C
Answer: D
Both B and C satisfy W + R > N (where N=3). QUORUM/QUORUM = 2+2=4 > 3. ONE/ALL = 1+3=4 > 3. Both guarantee reading the latest value.
Q29
The PACELC theorem extends CAP by asking:
A) What trade-off do you make when there is NO partition?
B) How many partitions can a system tolerate?
C) Whether to use SQL or NoSQL
D) How to merge conflicting data
Answer: A
PACELC extends CAP: during a Partition, choose A or C. Else (no partition), choose between Latency and Consistency. This captures the normal-operation trade-off that CAP ignores.
Q30
For a payment processing system within a messaging app, the best approach is:
A) Use eventual consistency for everything — it is the fastest
B) Use linearizability for everything — it is the most correct
C) Use linearizability for payments and eventual consistency with session guarantees for chat messages
D) Avoid distributed systems entirely
Answer: C
Per-feature consistency is the strongest answer. Payments require linearizability (wrong data = money lost). Chat messages can use eventual consistency with session guarantees for a good user experience.
Want to Land at Google, Microsoft or Apple?
Watch Pranjal Jain's free 30-min training — the exact GROW Strategy that helped 1,572+ engineers go from TCS/Infosys to top product companies with a 3–5X salary hike.
DSA + System Design roadmap 1:1 mentorship from ex-Microsoft Google login middot; Free forever
Stop solving random questions. Start with the right 206 DSA problems across 16 patterns — curated for product company interviews. Track your progress for free.