
What's Inside
Requirements & Scope
Clarifying Requirements
A URL shortener takes a long URL (https://www.example.com/very/long/path?param=value) and produces a short URL (https://sho.rt/abc1234) that redirects to the original. It sounds simple, but the design decisions around code generation, caching, analytics, and scaling make it the perfect system design interview question.

| Category | Requirement | Decision |
|---|---|---|
| In Scope | Create short URLs from long URLs | Core feature |
| In Scope | Redirect short URL → long URL | Core feature — the hot path |
| In Scope | Custom aliases (optional) | User-defined short codes |
| In Scope | URL expiration | TTL per URL |
| In Scope | Basic click analytics | Async via Kafka |
| Out of Scope | User accounts, dashboards, bulk creation, link-in-bio pages, QR codes | Skip for this interview |
| Non-Functional | 100M new URLs/month, 10B redirects/month | ~40 writes/sec, ~4,000 reads/sec |
| Non-Functional | Redirect latency <50ms | Drives 3-layer cache design |
| Non-Functional | 99.9% availability | ~8.7 hrs downtime/year |
| Non-Functional | URLs must never collide | Drives KGS design |
Back-of-Envelope Estimation
Quantifying the Scale

| Metric | Calculation | Result |
|---|---|---|
| Write QPS | 100M URLs/month ÷ 2.5M sec/month | ~40 writes/sec |
| Read QPS | 10B redirects/month ÷ 2.5M sec/month | ~4,000 reads/sec |
| Peak QPS | 4,000 × 2.5 | ~10,000 reads/sec |
| Read:Write ratio | 4,000 / 40 | 100:1 — very read-heavy |
| Storage | 100M URLs/month × 500 bytes × 60 months | 3 TB over 5 years |
| Bandwidth | 4,000 reads/sec × 500 bytes | 2 MB/sec (not a bottleneck) |
| Cache memory | 80/20 rule: top 20% of daily URLs × 500 bytes | 330 MB (one Redis instance) |
| Code length | 627 = 3.5 trillion unique codes | 7-char Base62 — more than enough |
"This is a read-heavy system at 100:1. I'll optimize reads with three cache layers: CDN, Redis, and PostgreSQL read replicas. 3 TB fits on one PostgreSQL node — no sharding initially. A single Redis instance (330 MB) caches the hot 20% of daily URLs. The 7-character Base62 code gives 3.5 trillion unique codes — more than sufficient."
API Design
Four Endpoints
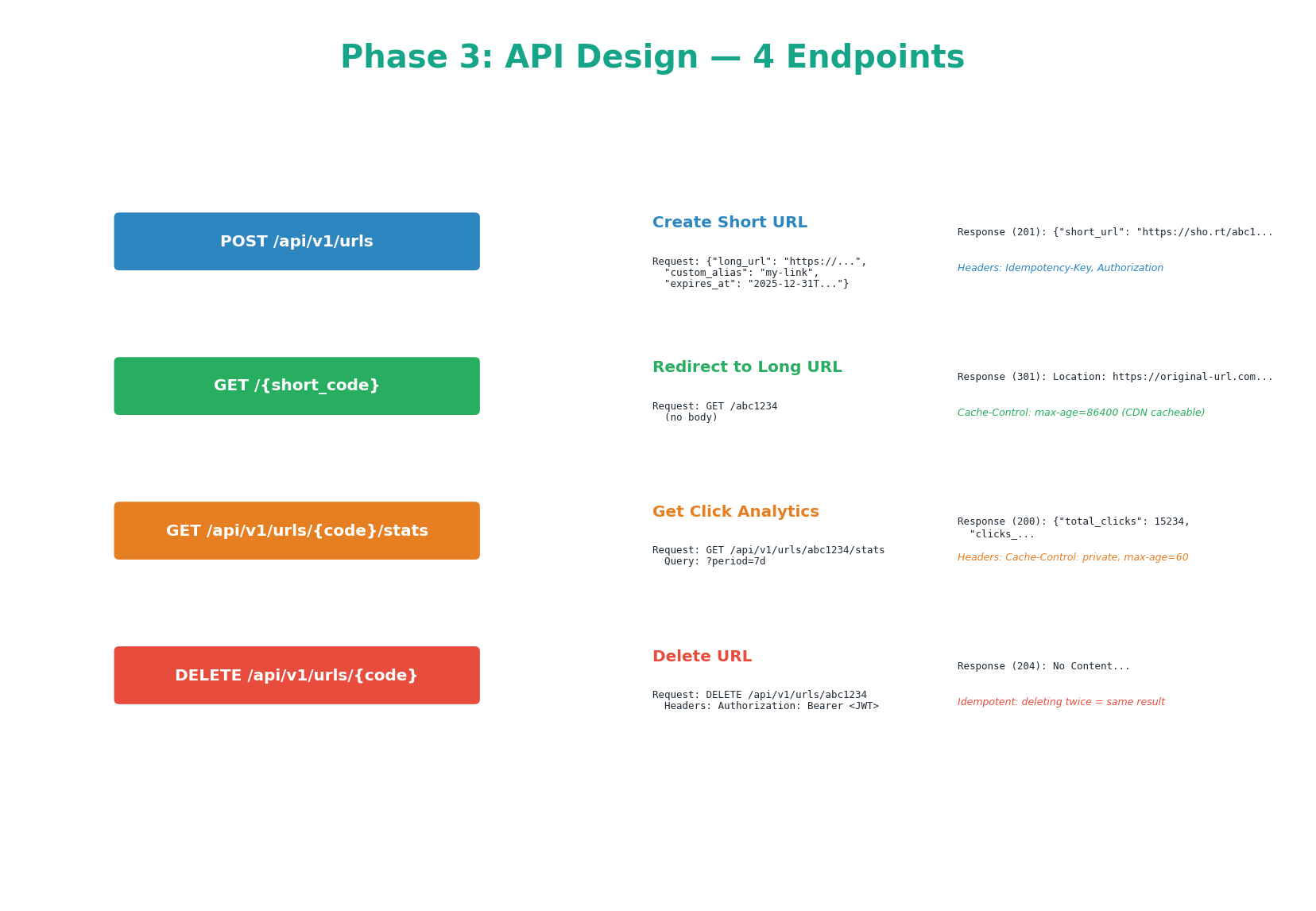
POST /api/v1/urls — Create Short URL
// POST /api/v1/urls // Headers: Authorization: Bearer <jwt>, Idempotency-Key: <uuid> { "long_url": "https://example.com/very/long/path", // required "custom_alias": "my-link", // optional, 3–20 chars "expires_at": "2026-12-31T23:59:59Z" // optional, ISO 8601 } // Response 201 Created { "short_url": "https://sho.rt/abc1234", "short_code": "abc1234", "long_url": "https://example.com/very/long/path", "created_at": "2026-03-26T10:00:00Z", "expires_at": "2026-12-31T23:59:59Z" }
If the same Idempotency-Key is sent twice (e.g., client retries after a timeout), the server returns the same short URL without creating a duplicate. Store key → response in Redis with a 24h TTL. Rate limit: 100 creates/minute per API key.
GET /{short_code} — Redirect (Hot Path)
// GET /abc1234 — the HOT PATH: 4,000 QPS, target <50ms HTTP/1.1 301 Moved Permanently Location: https://example.com/very/long/path Cache-Control: max-age=86400 // CDN caches for 24 hours // 404 Not Found if code unknown, expired, or deleted
301 Moved Permanently: the browser and CDN cache the redirect permanently. Subsequent visits never reach our servers. Faster and cheaper — but we lose per-click analytics (CDN serves cached 301 directly).
302 Found (Temporary): forces every visit through our server. We track every click, but lose CDN redirect caching and pay full latency for every redirect. Use 302 if analytics are a core requirement; use 301 if performance is the priority.
GET /api/v1/urls/{code}/stats — Analytics
{
"total_clicks": 84320,
"clicks_today": 1205,
"clicks_7d": 9842,
"created_at": "2026-03-26T10:00:00Z",
"expires_at": "2026-12-31T23:59:59Z"
}
DELETE /api/v1/urls/{code} — Delete URL
Soft delete: sets is_active = false in PostgreSQL. Subsequent redirects return 404. Response: 204 No Content. Idempotent — deleting an already-deleted URL also returns 204. Requires Authorization: Bearer JWT. Immediately deletes from Redis cache and triggers a CDN purge for the redirect path.
High-Level Design
The Complete Architecture
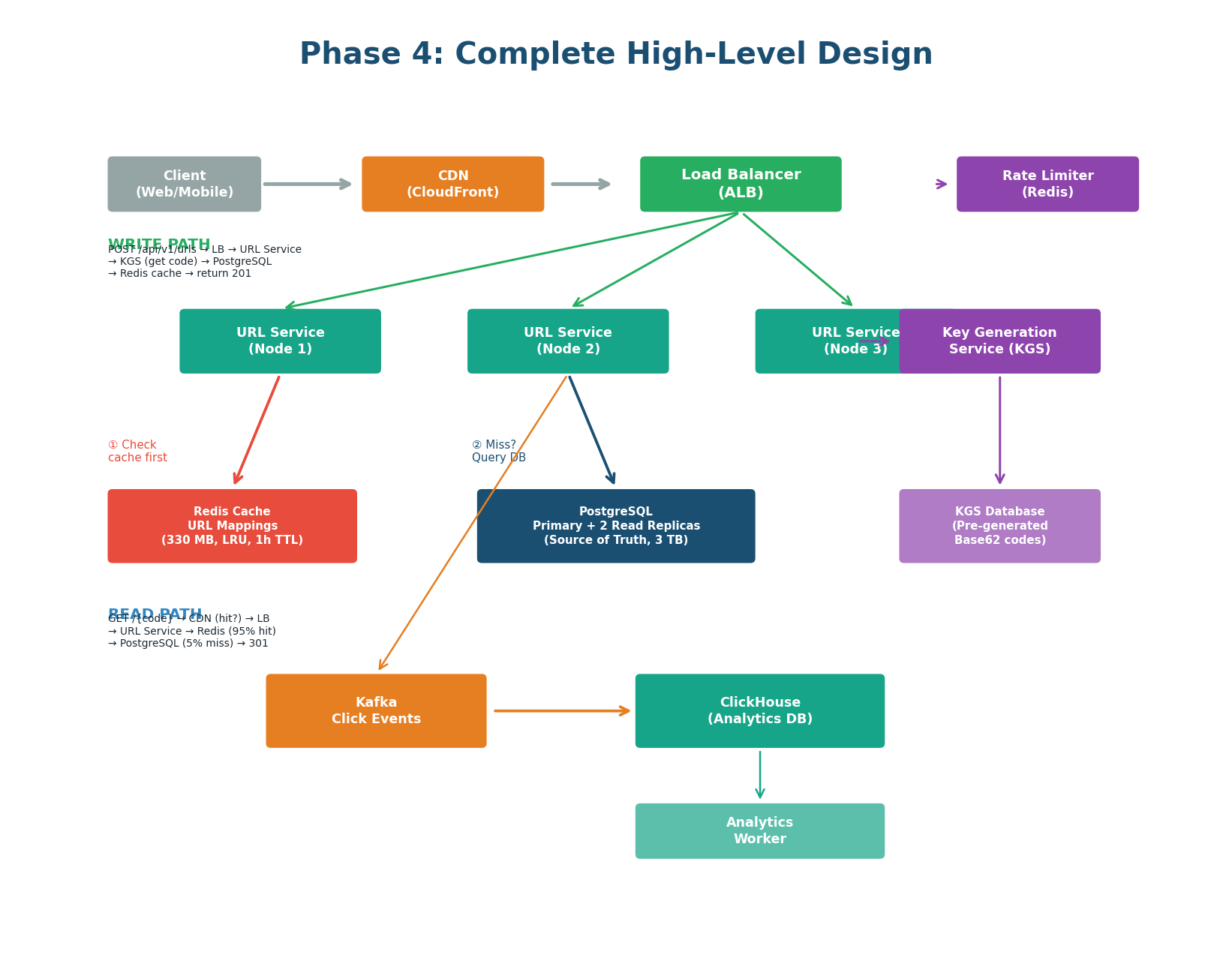
| Component | Technology | Role & Key Detail |
|---|---|---|
| CDN | CloudFront | Caches 301 redirects at the edge. Serves ~60% of redirect traffic at <5ms. Cache-Control: max-age=86400. |
| Load Balancer | ALB | Distributes across 3 URL Service instances. Least Connections algorithm. Health checks every 10s. |
| URL Service | Node.js / Go | Stateless. ~10K QPS per instance. 3 instances = 30K QPS capacity. Auto-scales when CPU > 70%. |
| Redis Cache | Redis 7 | 330 MB, LRU eviction, 1h TTL. Cache-aside. 95%+ hit rate. Key: url:{short_code} → long_url. |
| PostgreSQL | PostgreSQL 16 | Primary + 2 read replicas. Sync replication to one replica (zero data loss). Handles only ~5% of reads (200/sec). |
| Key Generation Service | KGS (custom) | Pre-generates millions of unique Base62 codes. Each URL Service pre-fetches 1,000 codes locally. Zero collision risk. |
| Analytics Pipeline | Kafka + ClickHouse | Every redirect publishes a click event async to Kafka. Workers aggregate into ClickHouse. Zero latency impact on redirect path. |
Short Code Generation
Three Approaches Compared

| Approach | How It Works | Problem | Use? |
|---|---|---|---|
| Hash + Truncate | MD5/SHA256 of long URL, take first 7 chars | Collision probability grows with scale. Two different URLs can produce the same 7-char prefix. | No |
| Auto-increment + Base62 | DB auto-increment ID, convert to Base62 | Predictable (sequential codes are guessable). Single DB write on every create (bottleneck at scale). | OK for small scale |
| Pre-generated KGS | Service pre-generates codes in batches, URL Service fetches from local buffer | Slightly more complex. KGS is a new service to operate. | Recommended |
KGS Implementation Details
The KGS maintains two tables: unused_codes (pre-generated codes not yet assigned) and used_codes (codes already given to URLs). When the URL Service needs a code, KGS atomically moves a code from unused to used and returns it. KGS pre-generates codes in batches of 10 million. With 627 = 3.5 trillion possible codes, we will never run out.
Each URL Service instance pre-fetches a batch of 1,000 codes from KGS into local memory. This means creates do not require a KGS call for every request — only when the local buffer runs out (~every 25 seconds at 40 writes/sec). If KGS is temporarily unavailable, the URL Service can continue creating URLs until its buffer is exhausted. This makes KGS a non-critical-path dependency.
Database Schema & Indexing
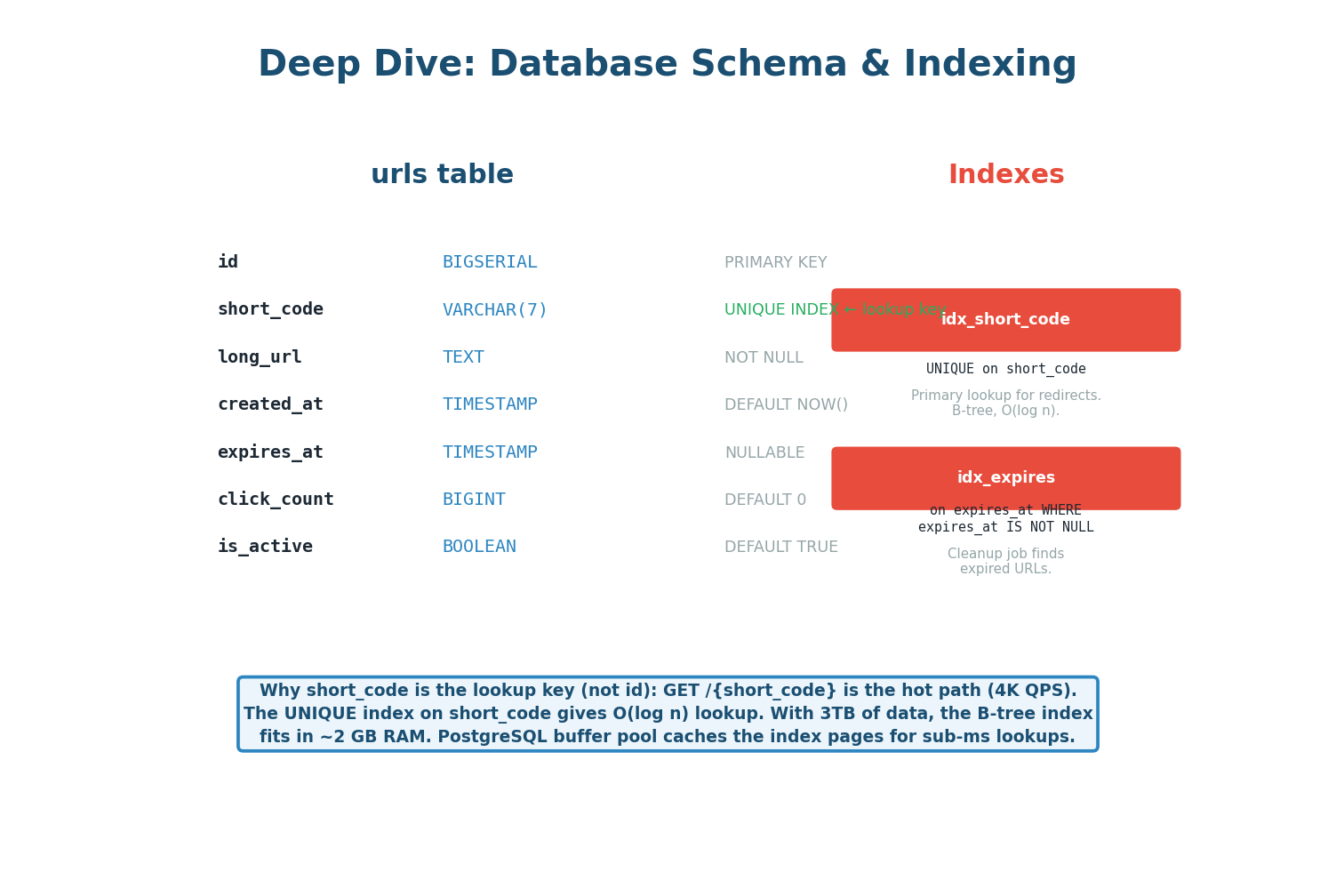
urls table schema with column types, constraints, and index strategyCREATE TABLE urls ( id BIGSERIAL PRIMARY KEY, short_code VARCHAR(10) NOT NULL UNIQUE, -- B-tree index, ~2 GB at 6B rows long_url TEXT NOT NULL, user_id BIGINT REFERENCES users(id), created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(), expires_at TIMESTAMPTZ, -- NULL = never expires is_active BOOLEAN NOT NULL DEFAULT TRUE -- soft delete flag ); -- Primary lookup: redirect path (the hot read) CREATE UNIQUE INDEX idx_urls_short_code ON urls (short_code) WHERE is_active = TRUE; -- For user dashboard + cleanup jobs CREATE INDEX idx_urls_user_created ON urls (user_id, created_at DESC); CREATE INDEX idx_urls_expires ON urls (expires_at) WHERE expires_at IS NOT NULL;
The short_code B-tree index is the primary lookup key for the redirect path. At 3 TB of data (~6 billion rows), the B-tree index is approximately 2 GB — small enough to fit entirely in PostgreSQL's shared_buffers (typically 8–16 GB). This gives sub-millisecond index lookups even without the Redis cache.
3-Layer Caching Strategy
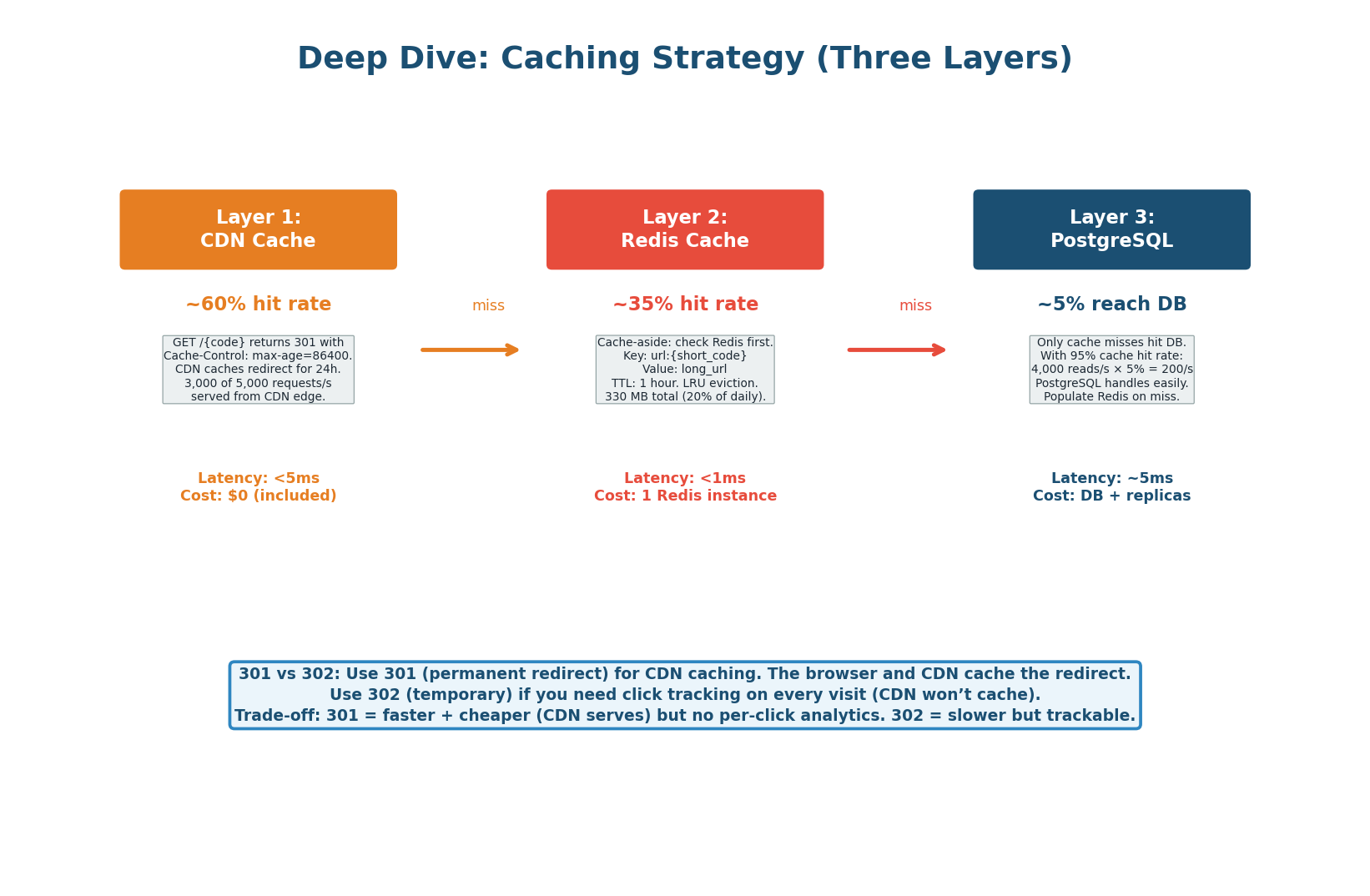
| Layer | Technology | Hit Rate | Latency | Key Config |
|---|---|---|---|---|
| Layer 1 | CDN (CloudFront) | ~60% | <5ms | Cache-Control: max-age=86400. 301 responses cached for 24h at edge. |
| Layer 2 | Redis | ~35% | <1ms | Cache-aside. Key: url:{code}. TTL: 1h. LRU eviction. 330 MB instance. |
| Layer 3 | PostgreSQL (read replica) | ~5% | ~5ms | Only ~200 reads/sec reach the DB. Well within capacity. Populates Redis on miss. |
Detailed Read & Write Paths
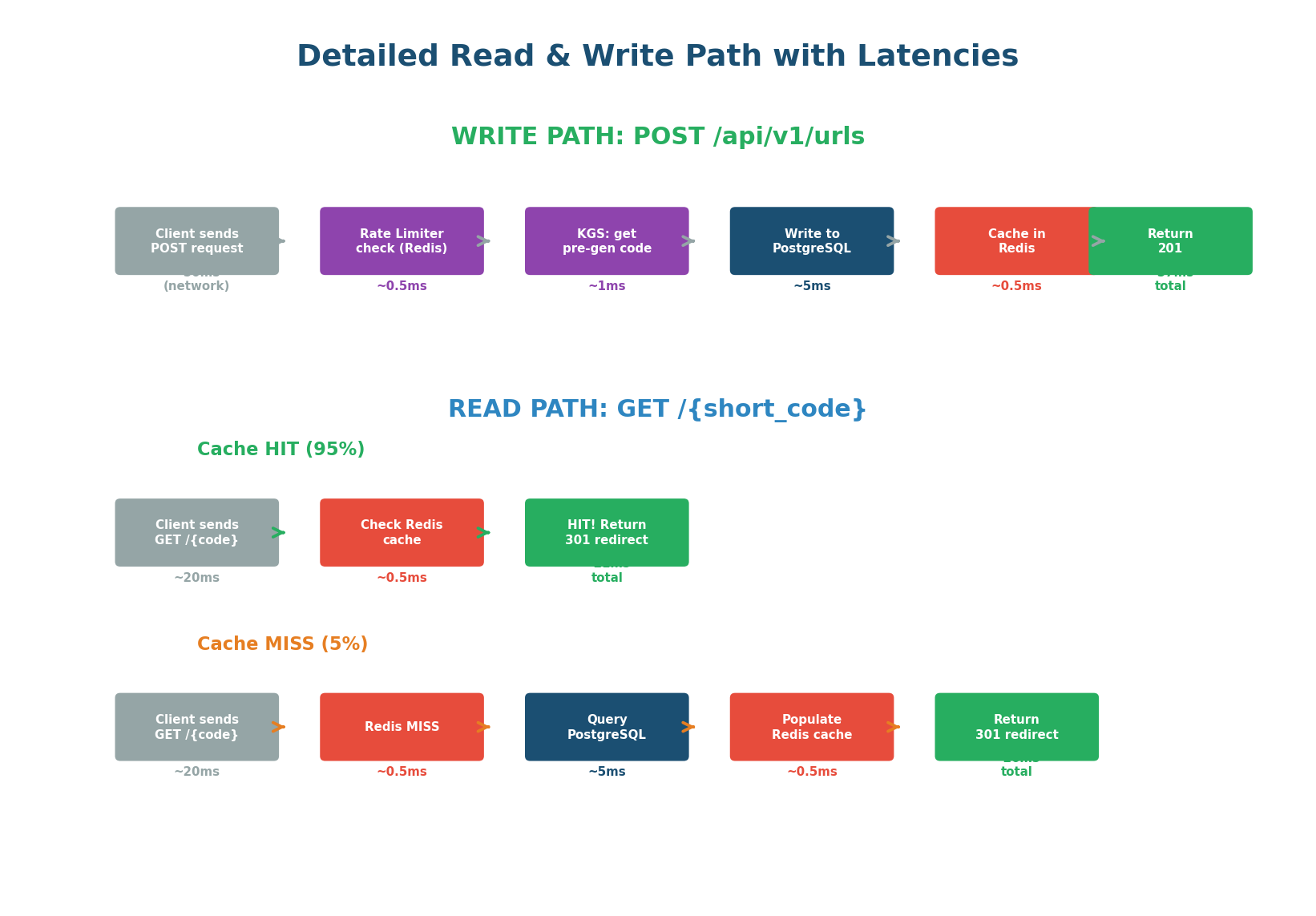
Write Path — POST /api/v1/urls — ~57ms total
INCR rate:{api_key} in Redis with 60s TTL. Returns 429 if over limit.INSERT into PostgreSQL primary with sync replica acknowledgmentSET url:{code} = long_url EX 3600 in RedisRead Path — GET /{code} — Cache Hit: ~21ms • Cache Miss: ~26ms
GET url:{code} returns long_url. Return 301/302.short_code index. Populate Redis. Return 301/302.Cache hit: ~21ms. Cache miss: ~26ms. Both are well within the <50ms non-functional requirement. The 3-layer cache does the heavy lifting: 60% of traffic never reaches our servers (CDN), 35% hits Redis at <1ms, and only 5% goes all the way to the database.
Trade-offs & Failure Scenarios
What Happens When Things Break
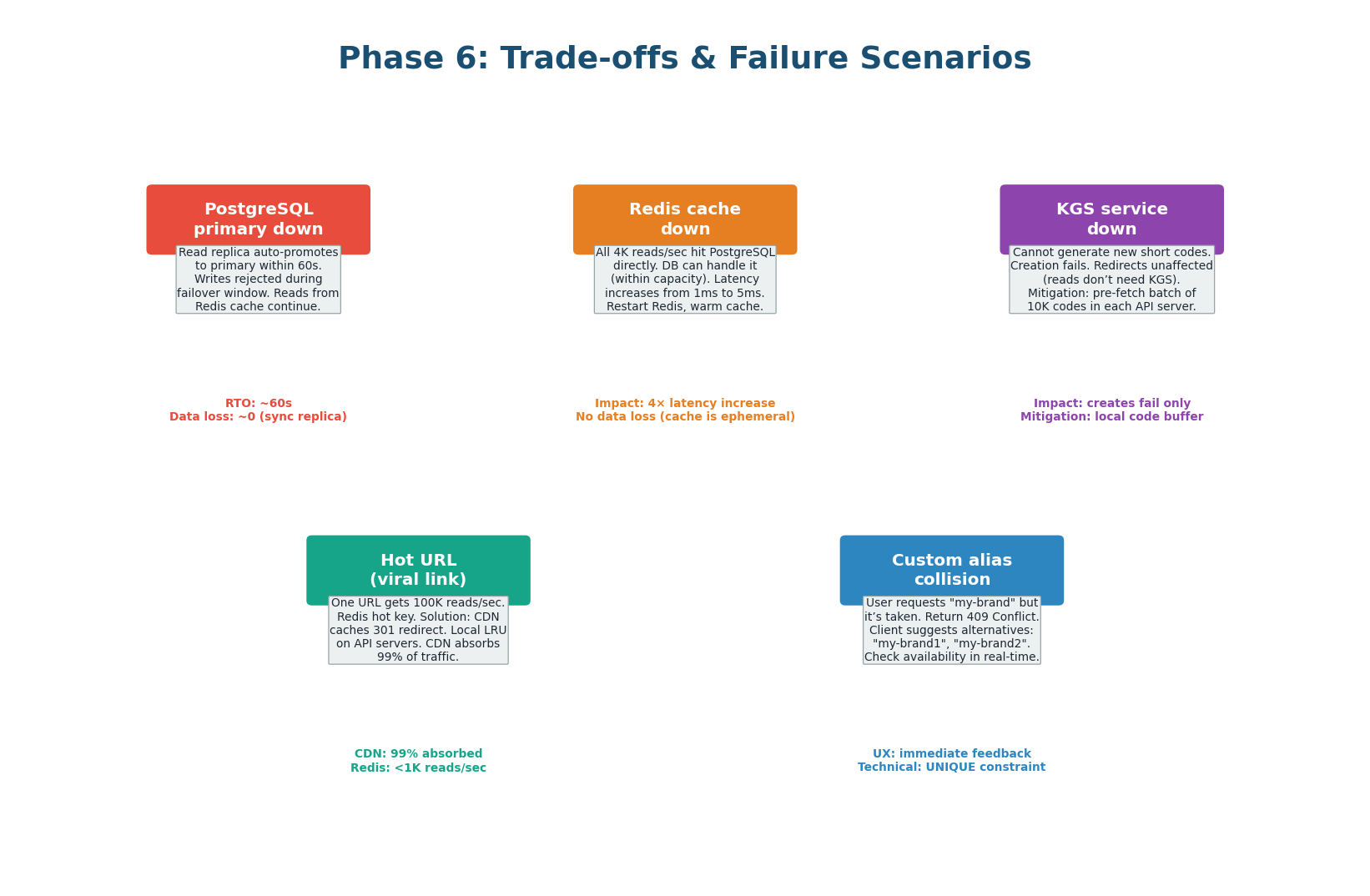
| Failure | Impact | Mitigation |
|---|---|---|
| Redis down | All reads fall through to PostgreSQL. 4,000 → 4,000 read/sec to DB (normally 200). DB can handle it short-term. | Redis Sentinel for auto-failover (<30s). DB read replicas absorb the surge. |
| PostgreSQL primary down | Writes fail. Reads continue from replicas + Redis cache. 95% of traffic unaffected. | Sync replica auto-promotes within 60s. Zero data loss (sync replication). Alert on-call. |
| KGS down | New URL creation fails once URL Service local buffer (~1,000 codes) exhausted. ~25 seconds of buffer. | KGS is stateless — restart quickly. Pre-fetch buffer buys time. Run 2 KGS instances for redundancy. |
| URL Service instance crash | ALB detects unhealthy instance within 20s and stops routing. Other instances absorb the load. | 3 instances at 10K QPS each = 30K total capacity. Even with 1 down: 20K > 10K peak. |
| Kafka / ClickHouse down | Analytics data loss. Zero impact on redirect performance (async pipeline). | Kafka persists events on disk. Analytics workers replay from last committed offset when recovered. |
Consistency Trade-offs
URL creation uses PostgreSQL ACID transactions. A created URL is immediately available because the write path populates both PostgreSQL (source of truth) and Redis (cache). Synchronous replication to one replica ensures zero data loss on primary failover.
Redis has a 1-hour TTL. If a URL is deleted, the cache may still serve the old redirect for up to 1 hour. For immediate deletion: delete from both Redis and PostgreSQL simultaneously in the DELETE handler. CDN cache is more aggressive (24 hours) — use the CDN's invalidation API for urgent deletions.
In the interview: Mention this explicitly. Say "I delete from Redis immediately, but CDN purge takes up to 60 seconds via the CloudFront API. For critical takedowns, I'd call the purge API immediately."
Scaling Plan
| Scale | Architecture Change |
|---|---|
| Current (100M URLs/month) | 1 PostgreSQL primary + 2 read replicas + 1 Redis (330MB) + 3 API servers + CDN. Handles 8K peak reads/sec. |
| 10× growth (1B URLs/month) | Add Redis memory (3.3 GB). Add API server instances (auto-scaling). Add PostgreSQL read replicas (4–6 total). Still no sharding needed. |
| 100× growth (10B URLs/month) | Shard PostgreSQL by hash(short_code) % N. Consistent hashing for easy rebalancing. Redis Cluster replaces single instance. Multiple KGS instances with partitioned code ranges. |
Wrap-Up & Design Checklist
The Interview Summary Statement
"To summarize: our URL shortener handles 100 million URLs per month with 4,000 redirects per second at under 50 milliseconds latency. The architecture uses a three-layer caching strategy (CDN, Redis, PostgreSQL) achieving 95%+ cache hit rate. Short codes are generated by a pre-generating Key Generation Service, eliminating collision risk entirely. Click analytics are processed asynchronously via Kafka and ClickHouse with zero impact on redirect latency. The system can scale from 100M to 1B URLs/month with no architectural changes — just more resources. Given more time, I would add geographic distribution with multi-region read replicas, a rate limiting dashboard, and URL validation against malware databases."

Want to Land at Google, Microsoft or Apple?
Watch Pranjal Jain's free 30-min training — the exact GROW Strategy that helped 1,572+ engineers go from TCS/Infosys to top product companies with a 3–5X salary hike.