
What's Inside
Topic 1
Load Balancing Algorithms Deep Dive
Why the Algorithm Matters
Choosing the right load balancing algorithm can mean the difference between a system that handles traffic gracefully and one that collapses under load. The algorithm determines which server receives each request, and a bad choice can leave some servers idle while others are overwhelmed. The pre-class covered the basics; now we go deeper into how these algorithms behave under real-world conditions.
Round Robin vs Least Connections: The Critical Difference
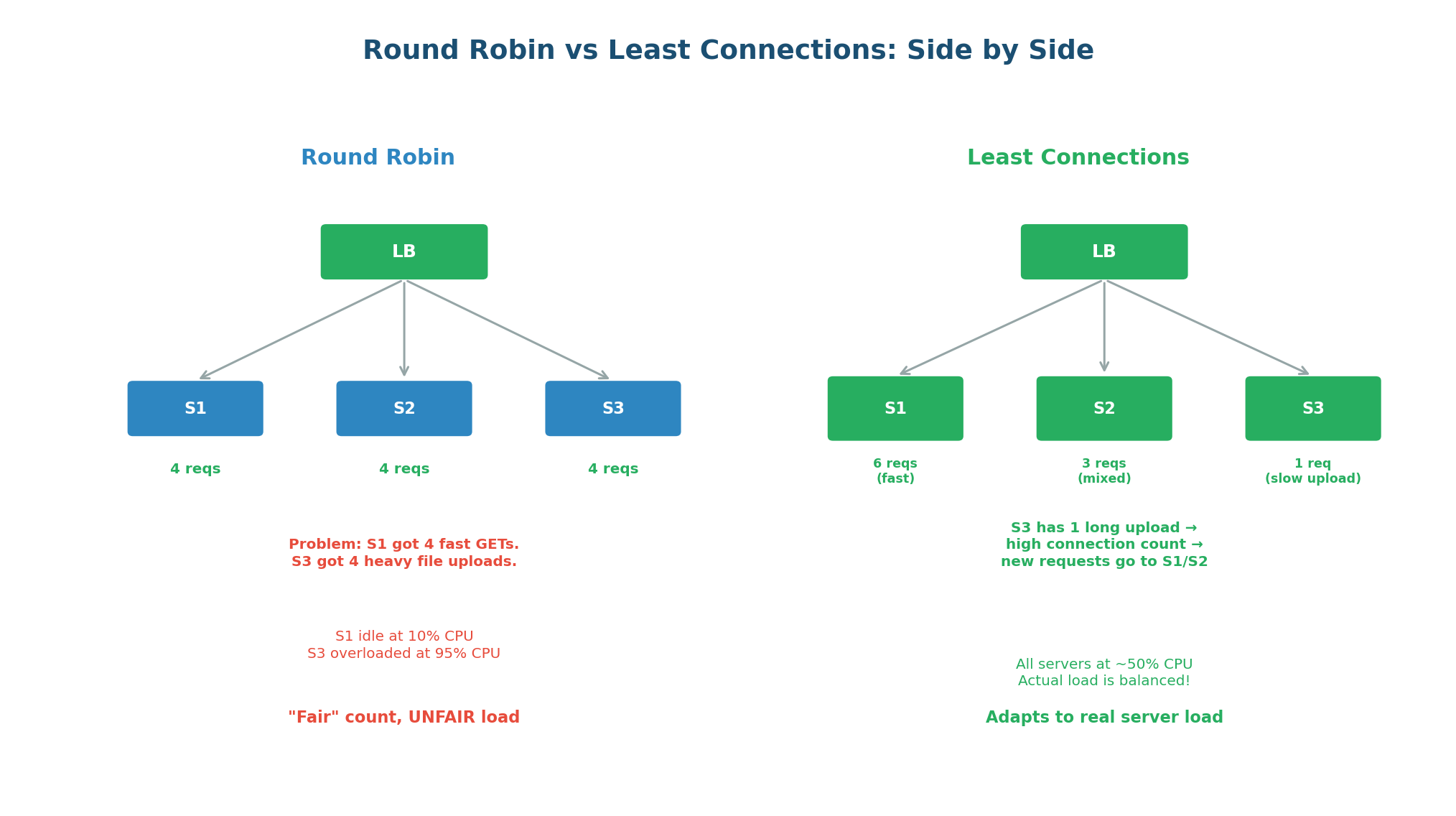
Round Robin gives each server the same number of requests. This sounds fair, but requests are not equal. A GET /health takes 1ms while a POST /upload with a 50MB file takes 30 seconds. If Server 3 receives 4 file uploads in a row while Server 1 gets 4 health checks, Server 3 is overwhelmed while Server 1 is idle — even though both got 4 requests.
Least Connections solves this by tracking how many active (in-flight) connections each server currently holds, and always routing new requests to the server with the fewest. If a server is processing a long-running upload, it will have a high connection count and will be skipped until it finishes. This adapts automatically to real server load, regardless of request duration.
| Algorithm | Routing Decision | Best For | Weakness |
|---|---|---|---|
| Round Robin | Next server in cycle | Uniform, short-lived requests | Ignores actual server load |
| Least Connections | Server with fewest active connections | Mixed request durations | Ignores server capacity differences |
| IP Hash | Hash of client IP | Session affinity (sticky sessions) | Uneven distribution if IPs cluster |
| Weighted Round Robin | Proportional to server weight | Heterogeneous server fleet | Still ignores actual load |
When an interviewer asks "what load balancing algorithm would you use?", say: "Least Connections is the best general-purpose default because it adapts to real server load. I would use Round Robin only if all requests are uniform and fast (e.g., a health check endpoint). For sticky sessions I would use Consistent Hashing or IP Hash. For mixed instance sizes I would use Weighted Least Connections." This shows you understand the trade-offs.
Advanced Algorithms for Specialized Scenarios
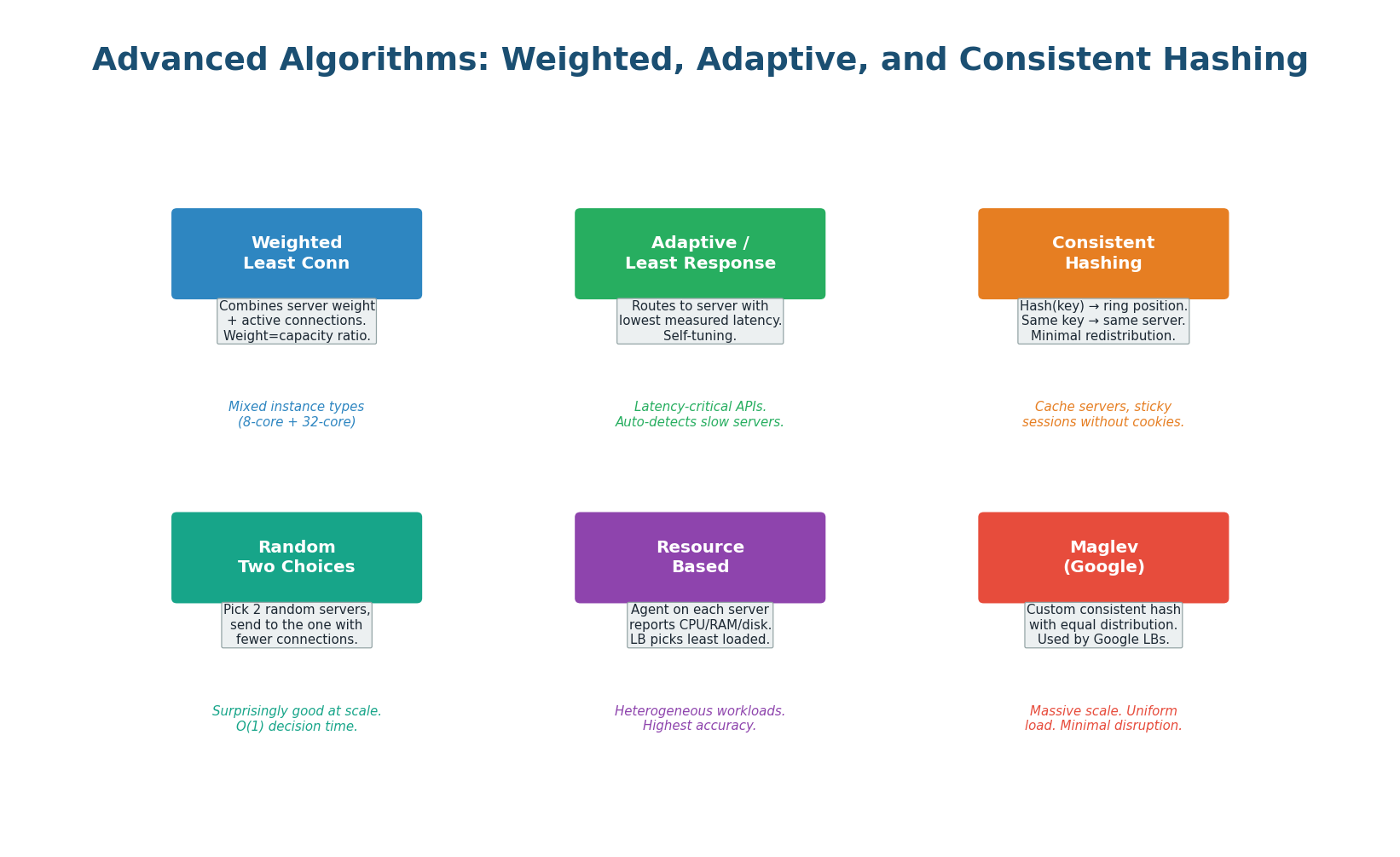
Weighted Least Connections combines server weights with connection counting. If Server A has weight 3 (powerful) and Server B has weight 1 (smaller), Server A is considered less loaded until it has 3x more connections than Server B. This is essential when you have a mix of instance types (e.g., c5.xlarge and c5.4xlarge in AWS). Without weights, both would get equal connections, and the smaller instance would be overwhelmed.
Power of Two Random Choices is a deceptively simple but remarkably effective algorithm: for each request, pick 2 servers at random and send the request to the one with fewer connections. Research shows this achieves exponentially better load distribution than pure random selection, with O(1) decision time. At massive scale (millions of servers), this outperforms Least Connections because maintaining a global connection count becomes a distributed systems bottleneck.
Consistent Hashing (for Load Balancers) uses a hash ring to route requests based on a key (session ID, user ID, or URL). The same key always maps to the same server, providing sticky sessions without cookies and ensuring cache locality (all requests for user 42 go to the same server where user 42's data is cached). When a server is added or removed, only ~1/N of keys are redistributed. This is how many caching proxies (Varnish, Nginx upstream) work internally.
Netflix's Zuul gateway uses a variant of Power of Two Random Choices for routing requests to microservices. At Netflix's scale, a centralized "least connections" counter would itself become a bottleneck requiring coordination across thousands of gateway instances. Picking 2 random servers and choosing the better one is O(1), stateless, and nearly as good as globally optimal — the best of both worlds.
Topic 2
DNS Load Balancing & Anycast Routing
DNS as a Load Balancer
DNS load balancing is the first layer of traffic distribution in any globally distributed system. Before a request even reaches your load balancer, DNS determines which region, data center, or edge server the user connects to. It operates at the domain name level — the user resolves api.example.com and DNS returns the IP address of the nearest or healthiest server cluster.
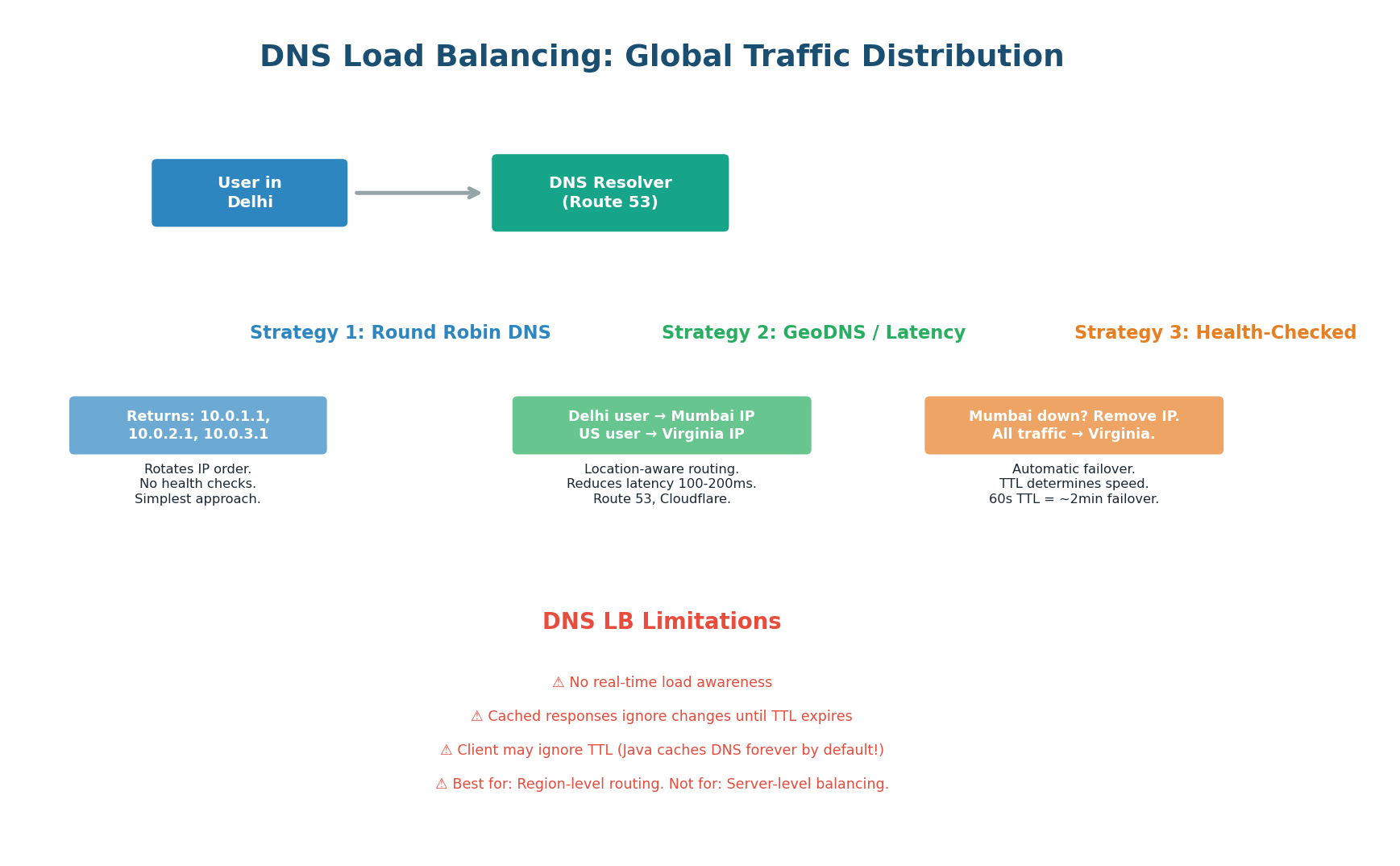
Three DNS Load Balancing Strategies
Round-Robin DNS: The simplest strategy. The authoritative DNS server returns multiple A records for the same domain, rotating their order with each query. User 1 gets 10.0.1.1, User 2 gets 10.0.2.1, User 3 gets 10.0.3.1, User 4 gets 10.0.1.1 again. The client typically uses the first IP. This distributes traffic across servers but has no health awareness — if 10.0.2.1 is dead, 33% of users still receive it and get errors until the TTL expires.
GeoDNS / Latency-Based Routing: The DNS server inspects the resolver's IP address to determine the user's approximate geographic location, then returns the IP of the nearest server. A user in Delhi resolves to the Mumbai server (10ms latency), while a user in New York resolves to the Virginia server (5ms latency). AWS Route 53 offers both geographic routing (fixed location-to-IP mappings) and latency-based routing (dynamically chooses the fastest endpoint).
Health-Checked DNS Failover: Route 53 and Cloudflare continuously monitor your endpoints with health checks. If the Mumbai server fails, DNS immediately stops returning its IP and routes all traffic to the next-best server (e.g., Singapore). The failover time equals the TTL: with a 60-second TTL, full failover takes 60–120 seconds (existing cached responses must expire). For faster failover, use lower TTLs (30 seconds) at the cost of higher DNS query volume.
Anycast Routing: Same IP, Nearest Server
Anycast is a routing technique where multiple servers in different geographic locations share the same IP address. When a packet is sent to an Anycast IP, the internet's routing infrastructure (BGP) delivers it to the nearest server. The user does not choose the server — the network itself routes to the closest one, automatically.
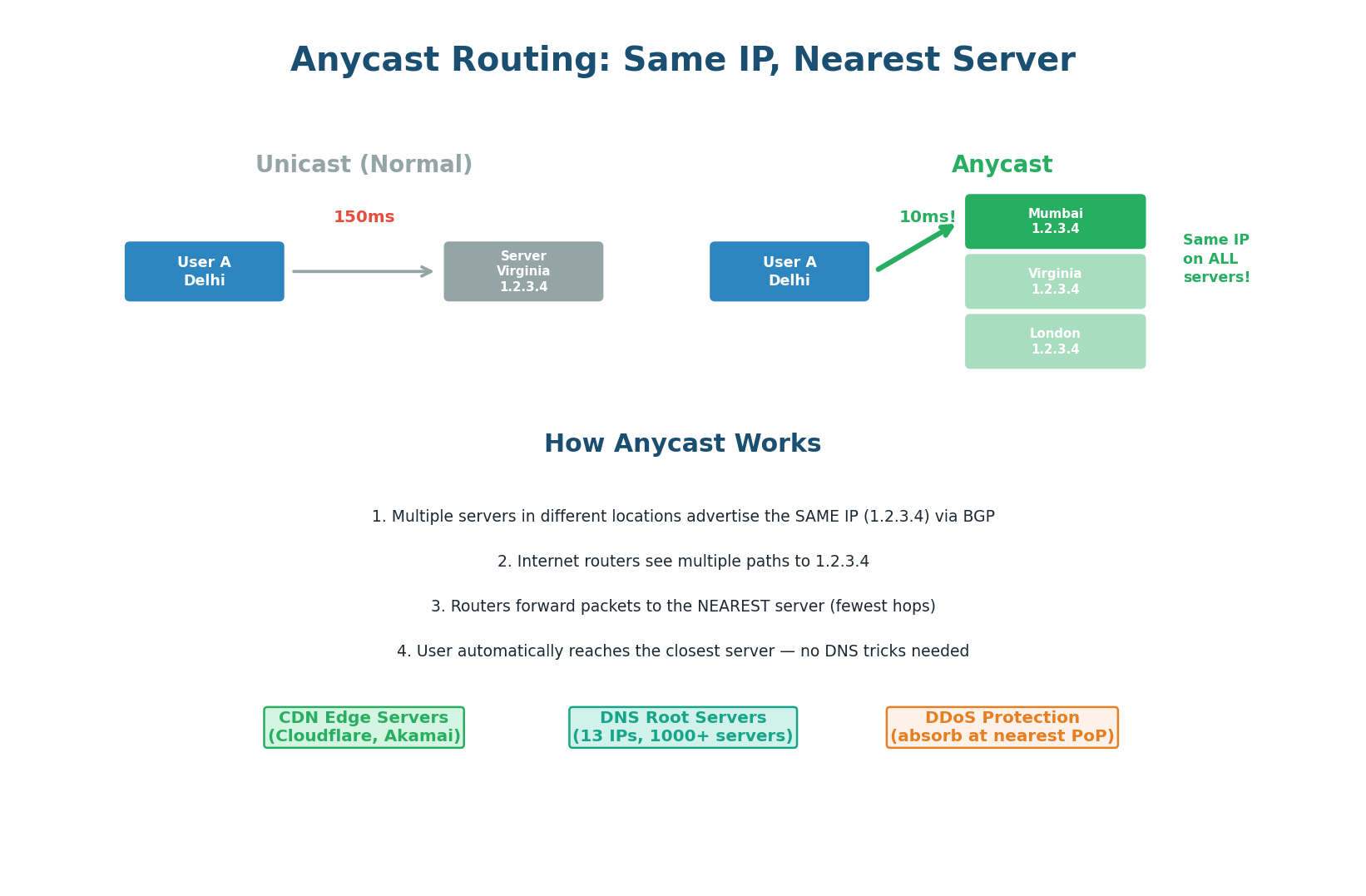
How Anycast Works:
- Multiple servers in different locations (Mumbai, Virginia, London) are configured with the same IP address (e.g., 1.2.3.4).
- Each server advertises this IP to its local internet exchange via BGP (Border Gateway Protocol).
- Internet routers see multiple paths to 1.2.3.4 and choose the shortest path (fewest hops, lowest latency).
- A user in Delhi sends a packet to 1.2.3.4 → routers forward it to Mumbai (3 hops away), not Virginia (15 hops away).
- If Mumbai goes down and stops advertising the IP via BGP, routers automatically re-route to the next-nearest server (Singapore or Virginia).
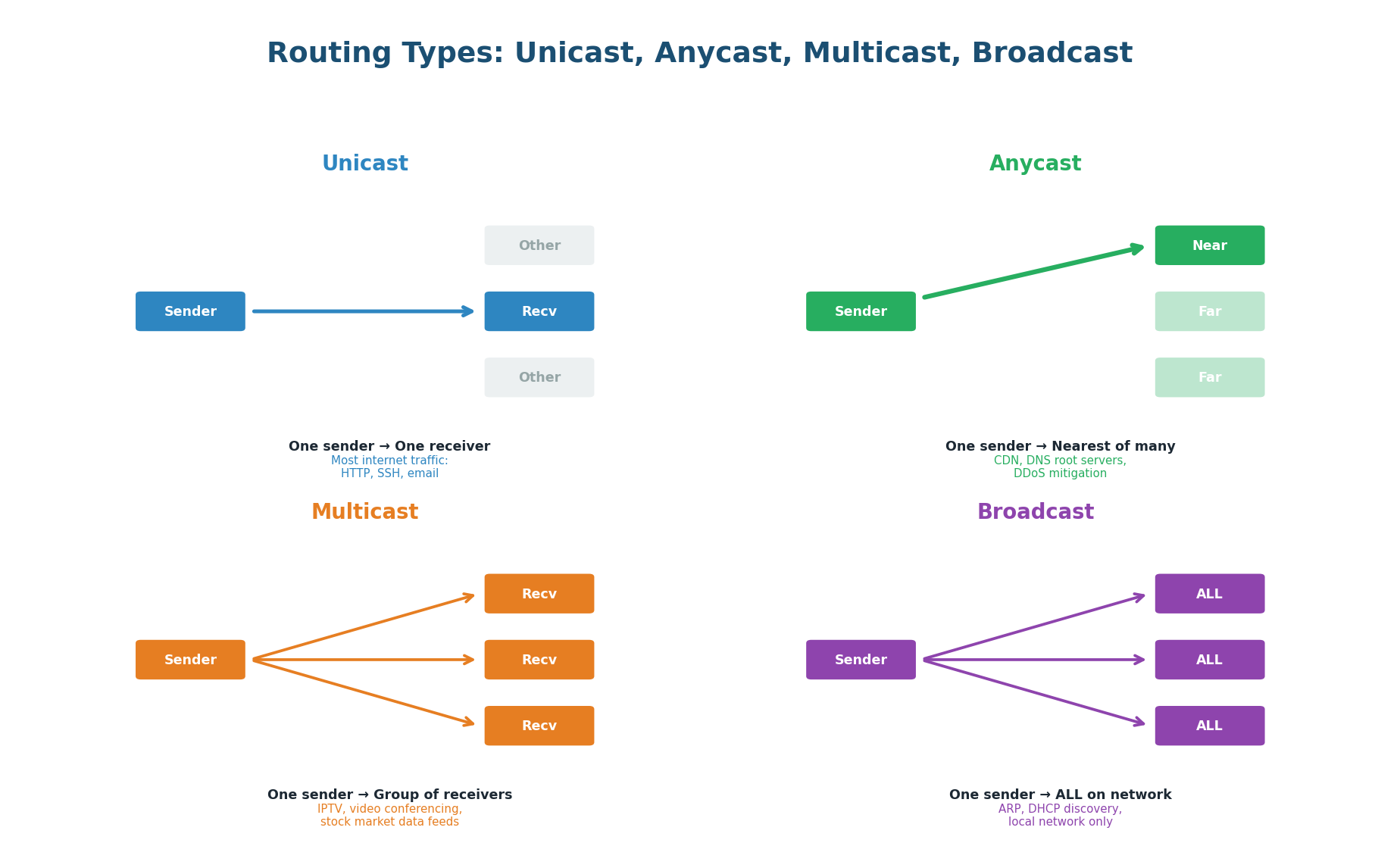
| Aspect | DNS-Based Routing | Anycast |
|---|---|---|
| Works at | DNS layer (application layer) | Network layer (BGP/IP routing) |
| Failover speed | Equal to DNS TTL (30–120 sec) | Seconds (BGP reconverges fast) |
| Geographic precision | Based on resolver IP (approx.) | Exact — based on network hops |
| Client awareness | Client gets different IPs per region | Client always sees same IP |
| DDoS absorption | Must route at DNS level | Attack traffic distributed across all PoPs automatically |
| Used by | AWS Route 53, Cloudflare DNS | Cloudflare edge, DNS root servers, Google 8.8.8.8 |
Anycast Use Cases in the Real World:
- CDN Edge Servers: Cloudflare operates 300+ data centers worldwide, all sharing Anycast IPs. Every user automatically connects to the nearest edge. This is why Cloudflare can absorb multi-terabit DDoS attacks — traffic is distributed globally by the network itself.
- DNS Root Servers: The 13 DNS root server "identities" (A through M) are actually 1,500+ physical servers worldwide using Anycast. When your resolver queries a root server, it reaches the nearest physical instance automatically.
- DDoS Mitigation: Anycast naturally distributes attack traffic across all Points of Presence (PoPs). A 1 Tbps attack aimed at one Anycast IP gets split across 300 locations, each absorbing only ~3.3 Gbps — manageable for any individual data center.
For global system design, mention both layers: "At the DNS layer I will use Route 53 with latency-based routing to direct users to the nearest region. Within each region, Anycast ensures users hit the nearest edge PoP. This gives us two levels of geographic routing — macro (region selection via DNS) and micro (PoP selection via Anycast) — resulting in sub-20ms latency to users worldwide."
Topic 3
Idempotency
What Is Idempotency and Why Does It Matter?
An operation is idempotent if performing it multiple times produces the same result as performing it once. In distributed systems, network failures, timeouts, and retries are inevitable. If a client sends a payment request and the network drops the response (not the request), the client does not know if the payment succeeded. It has two choices: do not retry (risk of failed payment) or retry (risk of double charge). Idempotency is the engineering solution that makes retries safe.
This is not a theoretical problem. Every payment processor, every e-commerce platform, and every financial system must handle this. Stripe, PayPal, and every bank API use idempotency keys. Understanding idempotency deeply is a differentiator in system design interviews.

HTTP Methods and Idempotency
The distinction matters for retry logic. If a GET or PUT request times out, you can safely retry it — the result will be the same. If a POST request times out, retrying might create a duplicate order, duplicate payment, or duplicate message. This is why non-idempotent operations need special handling.
| Method | Idempotent? | Safe to Retry? | Why |
|---|---|---|---|
| GET | Yes | Yes | Read-only; repeated calls return same data |
| PUT | Yes | Yes | Replaces resource; same payload = same result |
| DELETE | Yes | Yes | Deleting something twice = still deleted |
| POST | No | No (without key) | Creates new resource each time |
| PATCH | Sometimes | Depends | Incremental updates (e.g., += 1) are not idempotent; set operations are |
Idempotency Keys: Making POST Safe to Retry
The standard solution for making non-idempotent operations safe is the idempotency key. The client generates a unique key (typically a UUID) for each logical operation and sends it with the request in a header. The server stores this key along with the response. If the same key arrives again, the server returns the stored response without re-processing the request.

Implementation Pattern:
- Client generates a UUID:
Idempotency-Key: 550e8400-e29b-41d4-a716-446655440000 - Server receives request, checks if the key exists in the idempotency store (Redis or DB table).
- If the key does NOT exist: process the request normally, store the key + response, return the response.
- If the key DOES exist: skip processing entirely, return the stored response immediately.
- Keys expire after a window (24–72 hours) to prevent unbounded storage growth.
Stripe's API accepts an Idempotency-Key header on every write endpoint. If you charge a customer and the response is lost in transit, you retry with the same key. Stripe returns the original charge result — no double charge. Keys are stored for 24 hours. Stripe also locks concurrent requests with the same key (using Redis locks) to prevent race conditions where two retries arrive simultaneously before the first completes.
Idempotency Beyond Payments
Idempotency applies everywhere in distributed systems:
- Message Queues: Kafka and SQS guarantee "at-least-once delivery" — your consumer may receive the same message twice. Your consumer must be idempotent (e.g., check if the order was already processed before processing again).
- Database Operations: Use
INSERT ... ON CONFLICT DO NOTHING(PostgreSQL) orUPSERTpatterns instead of blind inserts. A retry inserts nothing if the row already exists. - Email / Notifications: Store a "sent" flag keyed by (user_id, event_id). Before sending, check if already sent. This prevents duplicate email alerts even if your notification service retries after a partial failure.
- Infrastructure as Code: Terraform, Ansible, and Kubernetes manifests are designed to be idempotent — applying the same configuration twice reaches the same desired state without side effects.
Most distributed systems provide "at-least-once" guarantees — your code will see messages/requests at least once but possibly more. "Exactly-once" delivery is extremely hard and expensive to guarantee end-to-end. The practical solution is to make your consumers idempotent and accept at-least-once delivery. This is the architecture Kafka, SQS, and most event-driven systems are designed around.
Topic 4
API Data Formats
How Data Is Encoded for Transmission
When an API sends data over the network, the data must be serialized (converted from in-memory objects to a byte stream) for transmission and deserialized (converted back to objects) at the receiving end. The choice of serialization format affects three things: payload size (bandwidth), serialization speed (CPU), and developer experience (readability and debugging). The three main formats in modern systems are JSON, Protocol Buffers, and XML.

JSON: The Universal Standard
JSON (JavaScript Object Notation) is a text-based, human-readable format that has become the de facto standard for web APIs. It is natively supported by JavaScript, has parsers in every language, and is easy to read and debug. When you call any REST API (Stripe, GitHub, Twitter), you almost certainly receive JSON.
Strengths: Human-readable and self-describing (field names are included). Universal browser support. Massive ecosystem (every HTTP client, every API testing tool). Easy to debug with curl, Postman, or browser dev tools.
Weaknesses: Text-based = larger payloads (field names repeated in every object). Slower parsing than binary formats. No built-in schema (you need JSON Schema or OpenAPI for validation). No native support for binary data (must base64-encode, adding 33% overhead).
Protocol Buffers: Binary Performance
Protocol Buffers (Protobuf), developed by Google, is a binary serialization format with a strict schema. You define your data structure in a .proto file, and the protobuf compiler generates code to serialize and deserialize. Field names are replaced by small integer tags, types are known at compile time, and the binary encoding is extremely compact.
Strengths: 2–10x smaller payloads than JSON (field names replaced by 1–2 byte tags). 5x faster serialization/deserialization. Strict schema = type safety and backward/forward compatibility. Language-neutral (generates code for Go, Java, Python, C++, etc.).
Weaknesses: Not human-readable (binary format). Requires schema (.proto file) and code generation step. Cannot inspect with curl or a browser. Debugging requires specialized tools (grpcurl, protobuf decoders).
XML: The Legacy Standard
XML (eXtensible Markup Language) was the dominant data format before JSON. It uses opening and closing tags similar to HTML. XML is verbose (field names appear twice per field — opening and closing tag), but offers powerful features like namespaces, XSD schema validation, and XSLT transformations. SOAP web services (common in banking and enterprise) use XML exclusively.
When you will encounter XML: Integrating with legacy enterprise systems, banking APIs (SOAP), government systems, and some payment gateways. In a greenfield system, there is almost never a reason to choose XML over JSON.
| Format | Size | Speed | Readability | Schema | Best For |
|---|---|---|---|---|---|
| JSON | Medium | Medium | High | Optional | Public APIs, browsers, external devs |
| Protobuf | Small (2–10x) | Fast (5x) | None (binary) | Required (.proto) | Internal service-to-service (gRPC) |
| XML | Large | Slow | Medium | Optional (XSD) | Legacy systems, SOAP, banking APIs |
| MessagePack | Small | Fast | None (binary) | None | JSON-compatible binary (Redis protocol) |
Content Negotiation: Agreeing on Format
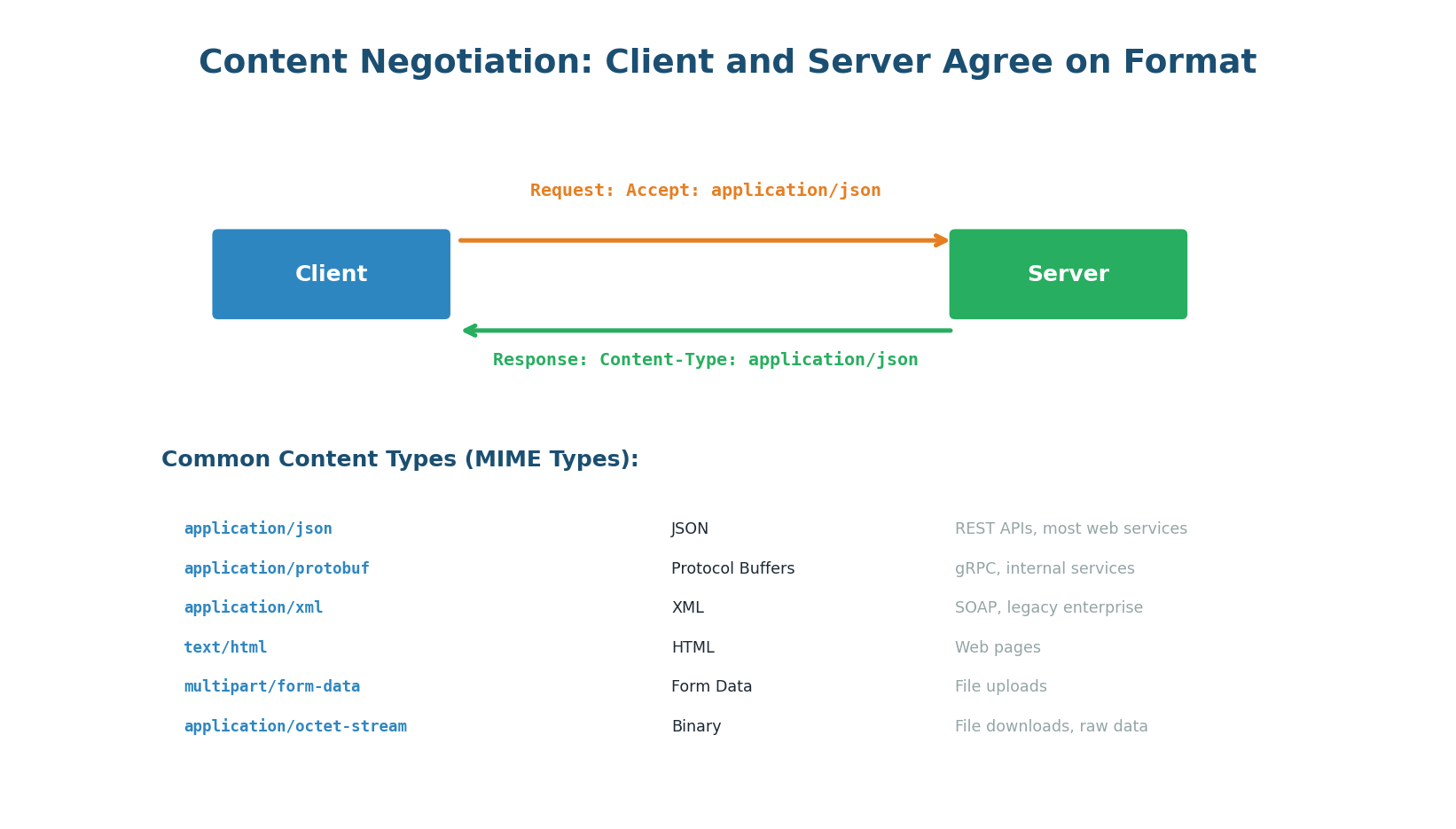
HTTP has a built-in mechanism for client and server to agree on data format: the Accept and Content-Type headers. The client sends Accept: application/json to request JSON. The server responds with Content-Type: application/json to confirm. If the server cannot provide the requested format, it returns 406 Not Acceptable. This allows a single endpoint to serve multiple formats: Accept: application/json for REST clients, Accept: application/x-protobuf for internal services.
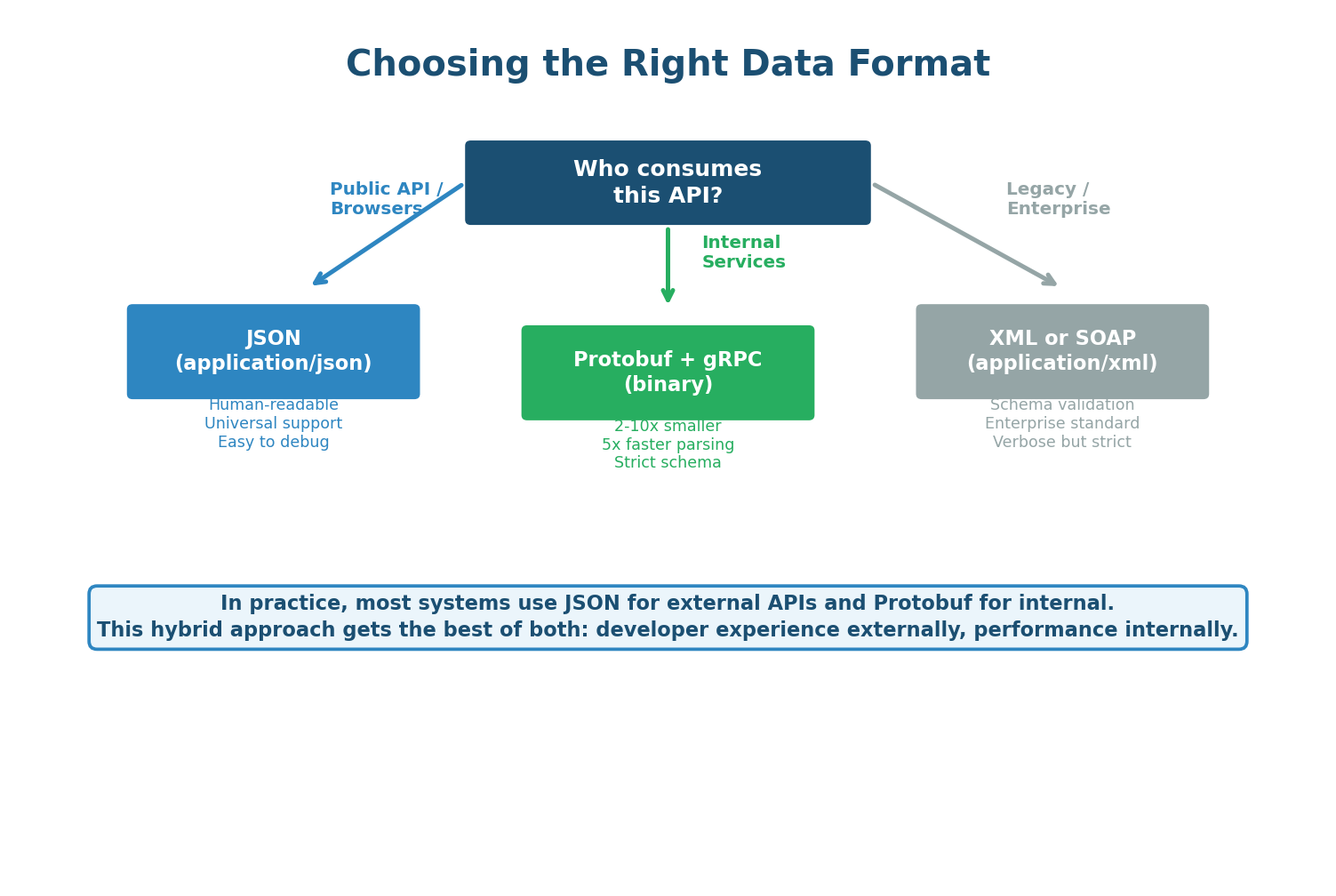
The decision is straightforward: use JSON for any API consumed by browsers, mobile apps, or external developers (95% of use cases). Use Protobuf with gRPC for internal service-to-service communication where performance matters and both sides control the code. Use XML only when integrating with legacy systems that require it. Many companies use a hybrid approach: JSON-based REST for public APIs and gRPC/Protobuf for the internal microservice mesh.
When asked about API design, mention the hybrid approach: "For the public-facing API I will use REST with JSON — it is the standard and every client can consume it easily. For internal service-to-service calls between the Order Service, Inventory Service, and Payment Service, I will use gRPC with Protobuf. This gives 5x better performance on the hot paths inside my system while keeping the public API developer-friendly."
Class Summary
Connecting the Four Topics
Load Balancing Algorithms determine which server receives each request. Least Connections is the best default because it adapts to real server load. Advanced algorithms like Consistent Hashing enable cache locality, and Power of Two Choices scales to massive deployments where centralized state becomes a bottleneck.
DNS Load Balancing and Anycast are the first two layers of traffic distribution, operating before the request even reaches your infrastructure. DNS routes users to the nearest region; Anycast routes packets to the nearest edge server at the network level. Together they deliver sub-10ms latency to users worldwide and absorb DDoS attacks through geographic distribution.
Idempotency is the safety net that makes distributed systems resilient to retries. Every write operation should support idempotency keys. Without them, network failures cause duplicate payments, duplicate orders, and duplicate messages — issues that are notoriously hard to debug and fix after the fact.
API Data Formats determine the wire efficiency of every API call. JSON is the standard for external APIs (developer experience), Protobuf with gRPC is the standard for internal services (performance), and XML exists for legacy integration. The hybrid approach gives you the best of both worlds: a friendly public API and a high-performance internal service mesh.
Want to Land at Google, Microsoft or Apple?
Watch Pranjal Jain's free 30-min training — the exact GROW Strategy that helped 1,572+ engineers go from TCS/Infosys to top product companies with a 3–5X salary hike.