
Contents
Today's Walkthrough Roadmap
This is a complete, end-to-end system design walkthrough of the URL shortener. Requirements and estimation were covered in Class 9. Today we go deep into the four areas that interviewers score most heavily: Database Design, Caching Strategy, Scaling Plan, and Trade-offs. These four deep dives are what separate a "Hire" from a "Strong Hire."

"At this point in the interview, I've already: (1) asked 8 clarifying questions, (2) estimated 40 writes/s and 4K reads/s, (3) defined 4 API endpoints, and (4) drawn the high-level architecture. Now let me deep dive into the database design. I'll start with the schema and indexing strategy, then cover the caching layers, and finally discuss scaling and failure scenarios."
Database Design — Schema, Indexes & Key Generation
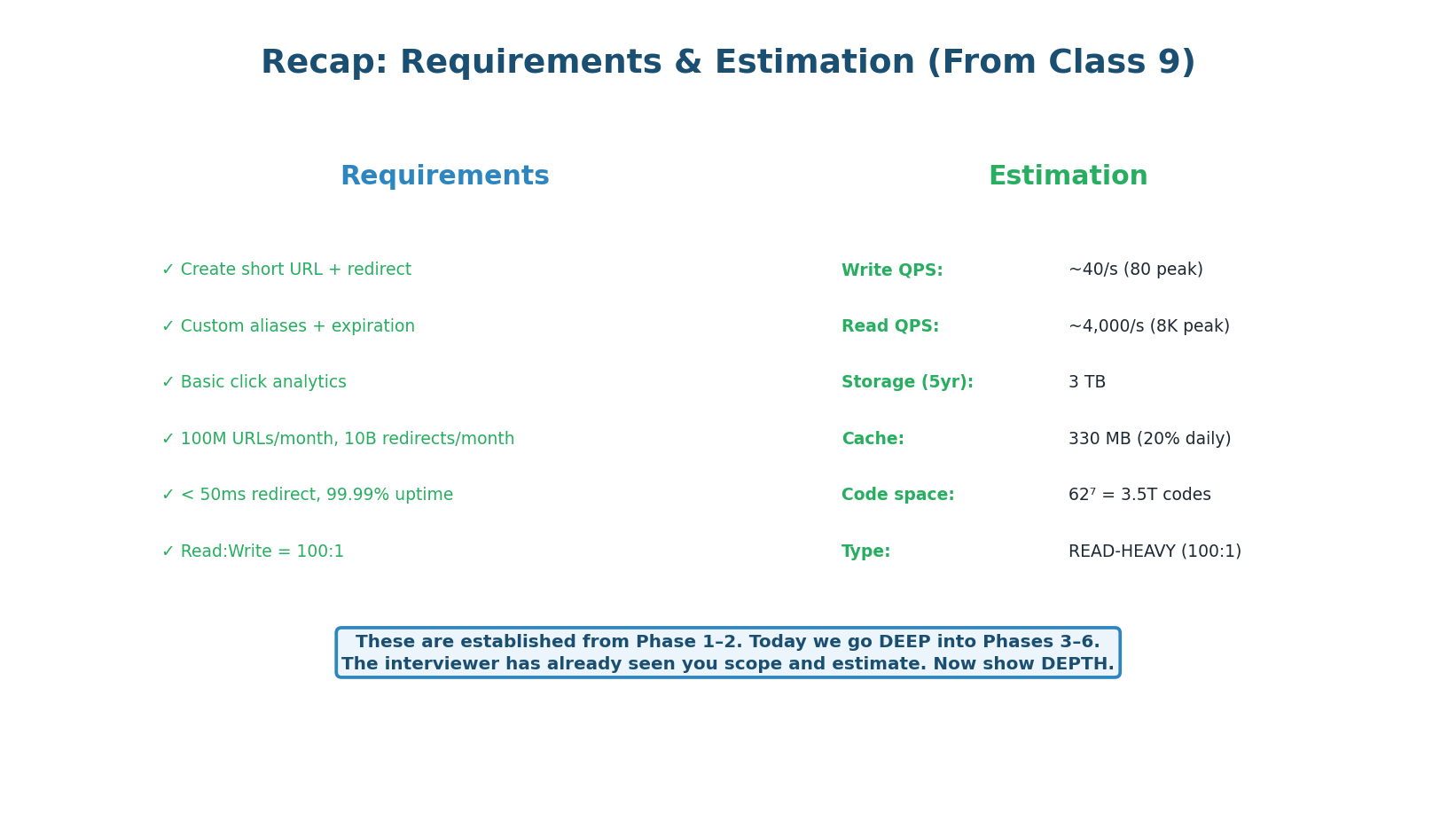
The database design is the foundation of the URL shortener. Every redirect (4,000/sec) and every create (40/sec) touches the database — either directly or through the cache. The schema must be optimized for the hottest query: SELECT long_url FROM urls WHERE short_code = ?. This means the short_code column needs a UNIQUE B-tree index that fits in memory for sub-millisecond lookups.
The urls Table: 8 Columns
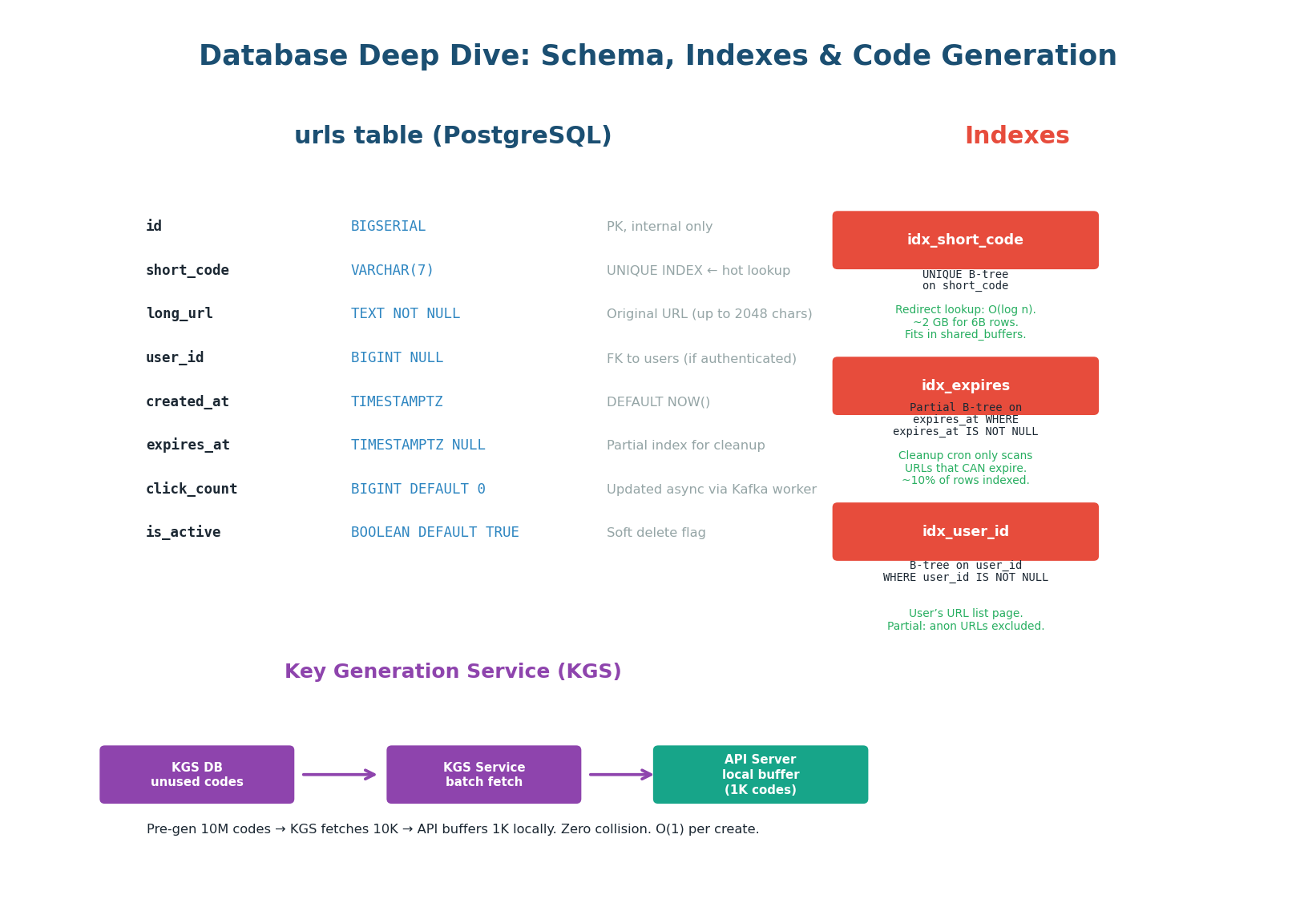
| Column | Type | Why This Choice |
|---|---|---|
id |
BIGSERIAL | Internal primary key. Never exposed to users. Used for DB operations only. |
short_code |
VARCHAR(7) | 7-char Base62 code. UNIQUE INDEX = O(log n) lookup for the redirect hot path. |
long_url |
TEXT NOT NULL | Original URL. TEXT (not VARCHAR) because URLs can be up to 2,048 chars. |
user_id |
BIGINT NULL | FK to users table. NULL for anonymous creates. Partial index (non-null only). |
created_at |
TIMESTAMPTZ | DEFAULT NOW(). Used for analytics and sorting user's URL list. |
expires_at |
TIMESTAMPTZ NULL | Partial index: only non-null rows indexed. Cleanup cron scans this index. |
click_count |
BIGINT DEFAULT 0 | Updated ASYNC via Kafka worker. Never updated in the redirect hot path. |
is_active |
BOOLEAN DEFAULT TRUE | Soft delete. DELETE endpoint sets false. Redirect returns 404 if false. |
Index Strategy: Why These Three Indexes
-
idx_short_code (UNIQUE B-tree): This is the critical index. Every redirect does:
SELECT long_url FROM urls WHERE short_code = 'abc1234'. The B-tree gives O(log n) lookup. With 6 billion rows, the index is ~2 GB. PostgreSQL'sshared_buffers(configured at 8–16 GB) keeps the entire index in RAM — sub-millisecond lookups guaranteed. -
idx_expires (Partial B-tree): Only indexes rows WHERE
expires_at IS NOT NULL. If 10% of URLs have expiration, this index covers only 10% of rows. The hourly cleanup cron runs:DELETE FROM urls WHERE expires_at < NOW() AND is_active = true. The partial index makes this efficient regardless of total table size. -
idx_user_id (Partial B-tree): Only indexes rows WHERE
user_id IS NOT NULL. Used for the "my URLs" list page. Without this, fetching a user's URLs would require a full table scan of 6 billion rows. With the partial index, it is O(log n) with a much smaller index.
Updating click_count in the redirect hot path would mean: SELECT long_url + UPDATE click_count for every redirect = 4,000 writes/sec to the DB for a read-heavy system. Instead, the redirect path publishes a click event to Kafka. An analytics worker batches events and updates click_count in bulk every 10 seconds. This keeps the redirect path read-only from DB and write load low.
Write Path: 5 Steps with SQL
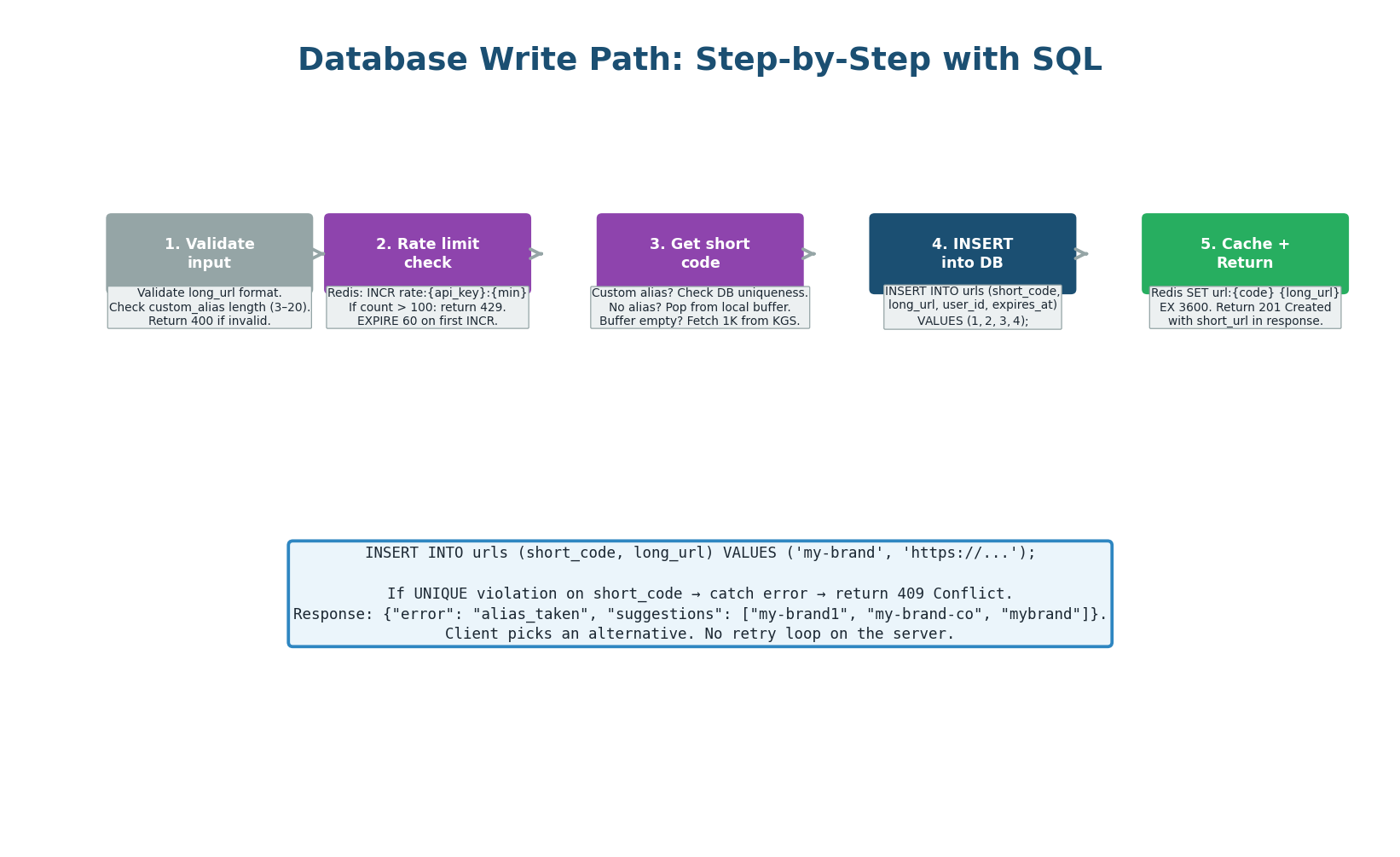
The write path handles POST /api/v1/urls at 40 requests/second. Each step is designed to fail fast: input validation first (no DB call needed), rate limit check (one Redis call), code generation (from local buffer, no network call), then the database INSERT, and finally cache population. Total server-side time: ~7ms.
"When a user creates a URL: first I validate the input — is the long_url a valid URL? Is the custom alias within 3–20 characters? If invalid, return 400 immediately. Then I check the rate limiter in Redis: INCR the user's counter for this minute. If over 100, return 429. Next, I get a short code: if the user specified a custom alias, I try to INSERT it (UNIQUE constraint catches collisions → return 409). If no alias, I pop a pre-generated code from the local buffer (O(1), no network call). Then INSERT into PostgreSQL — ~5ms with sync replication. Finally, I cache the mapping in Redis with a 1-hour TTL and return 201."
Caching Strategy — Three-Layer Cache with Decision Flow
The caching strategy is the most important design decision for a read-heavy system (100:1 ratio). Without caching, 4,000 reads/sec hit PostgreSQL directly. With the three-layer strategy (CDN + Redis + DB), only ~200 reads/sec (5%) reach the database. The cache hit rate is the single most important metric for this system.
Three-Layer Cache: CDN + Redis + PostgreSQL
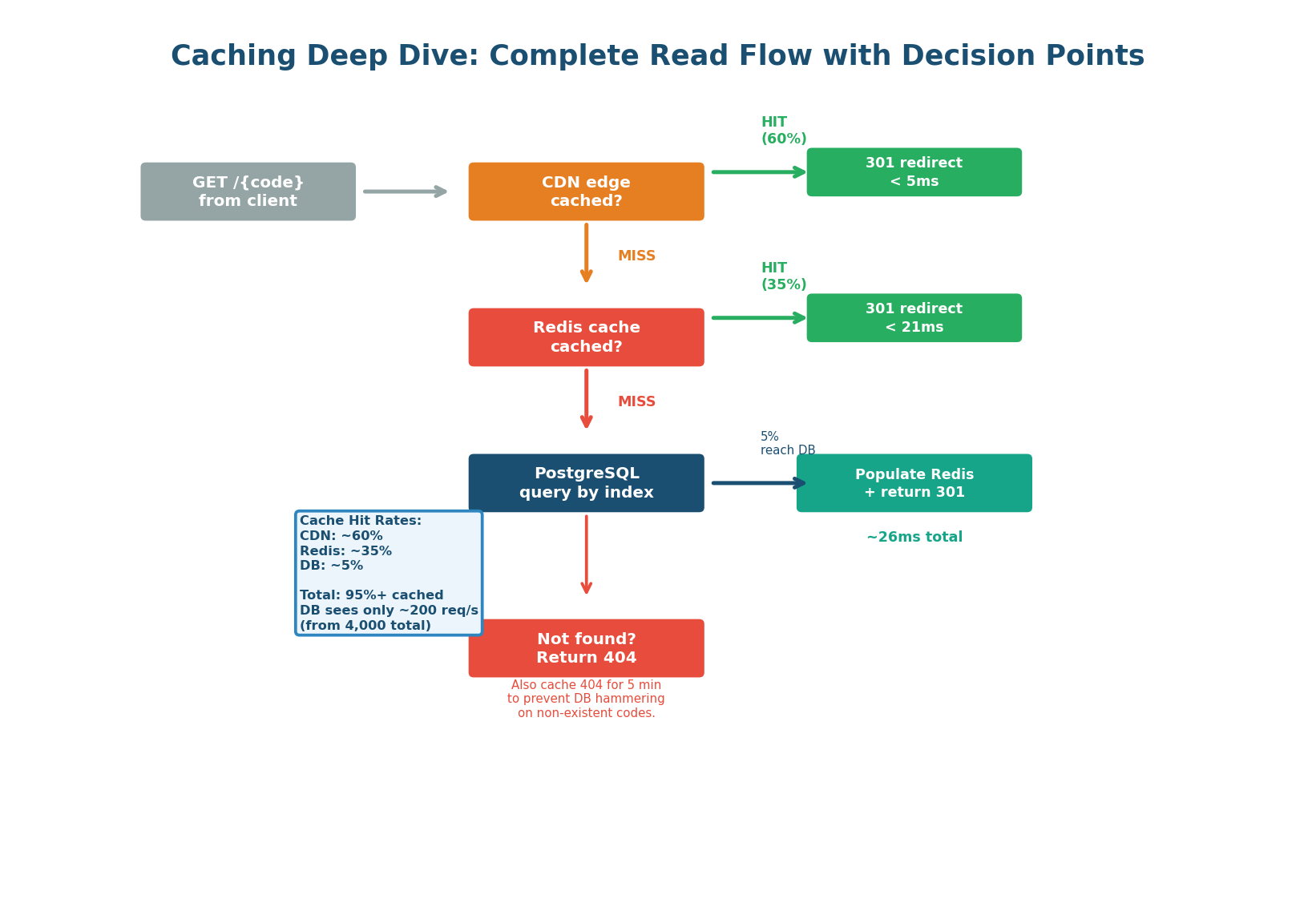
Cache-Control: max-age=86400. CloudFront caches the redirect at 400+ edge locations. A user in Delhi gets the redirect from Mumbai (~5ms) instead of US-East origin (~150ms). Trade-off: 301 means no per-click analytics. If analytics is required, use 302 instead.GET url:abc1234. Hit = return long URL immediately (<1ms). Miss = fall through to PostgreSQL. Redis stores the top 20% of daily URLs (hot set) with 1-hour TTL and allkeys-lru eviction. Also caches 404s: SET url:nonexistent "__NOTFOUND__" EX 300 for 5 minutes."I also cache 404 Not Found responses in Redis with a 5-minute TTL. If a non-existent short code gets 1,000 requests (bot attack, typo in a popular tweet), the first request queries PostgreSQL and gets no result. I cache url:nonexistent = __NOTFOUND__ EX 300. The next 999 requests hit Redis and return 404 without touching the DB. This prevents DB hammering from invalid codes." This shows production thinking — most candidates miss it.
Redis Configuration: Every Setting

| Config | Value | Why |
|---|---|---|
maxmemory |
512 MB | Cache is ~330 MB. 512 MB provides growth headroom. |
maxmemory-policy |
allkeys-lru | Evicts coldest URLs when full. Hot URLs stay in cache automatically. |
save |
60 1000 | RDB snapshot every 60s if 1,000+ keys changed. For recovery. Source of truth = PostgreSQL. |
appendonly |
yes, everysec | AOF for durability. Max 1 second data loss on crash. Acceptable for a cache layer. |
| Replication | 1 replica + Sentinel | Auto-failover in ~10s if primary dies. Three Sentinel processes monitor. |
| Key format | url:{short_code} |
GET url:abc1234 → 'https://original-url.com'. Namespaced to avoid collisions. |
| TTL | 3600 seconds (1 hour) | Fresh enough for URL redirects. Re-populated from DB on cache miss. |
Scaling Plan — Three Stages from Day 1 to 100×
A good scaling plan describes not just the final state, but the progression from today's architecture to future scale. This shows the interviewer you understand that premature optimization is wasteful and that you scale incrementally based on metrics, not guesses. Each stage has clear triggers for moving to the next.
Scaling Stages with Specific Triggers
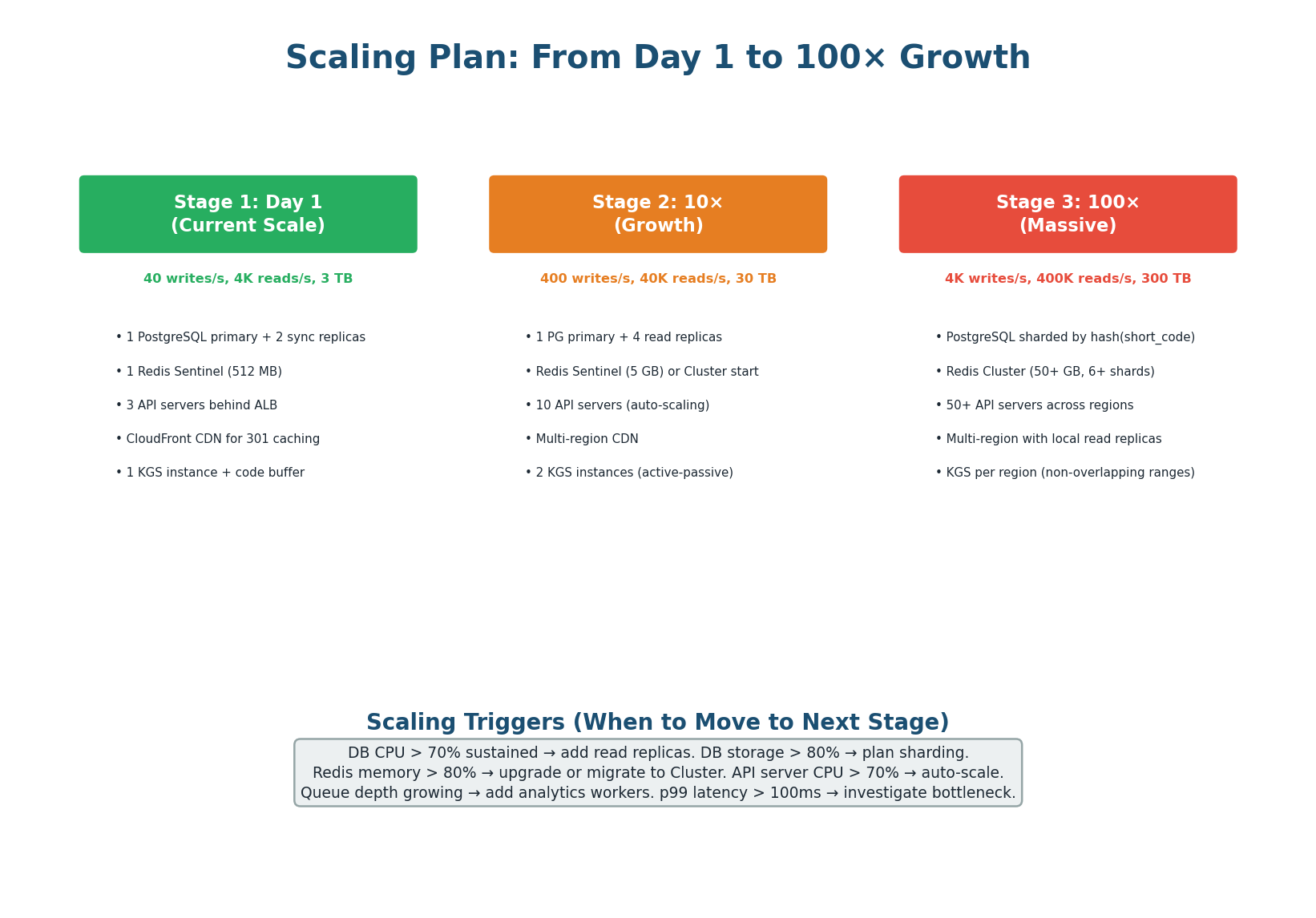
1 PG primary + 2 sync replicas
1 Redis Sentinel (512 MB)
3 API servers • CloudFront CDN
Cost: ~$2,000–3,000/month
4 PG read replicas total
Redis 5 GB (still Sentinel)
10 API servers (auto-scaled)
2nd KGS instance (active-passive)
PG sharded by hash(short_code)
Redis Cluster (50+ GB, 6+ shards)
50+ API servers across regions
KGS per region with code ranges
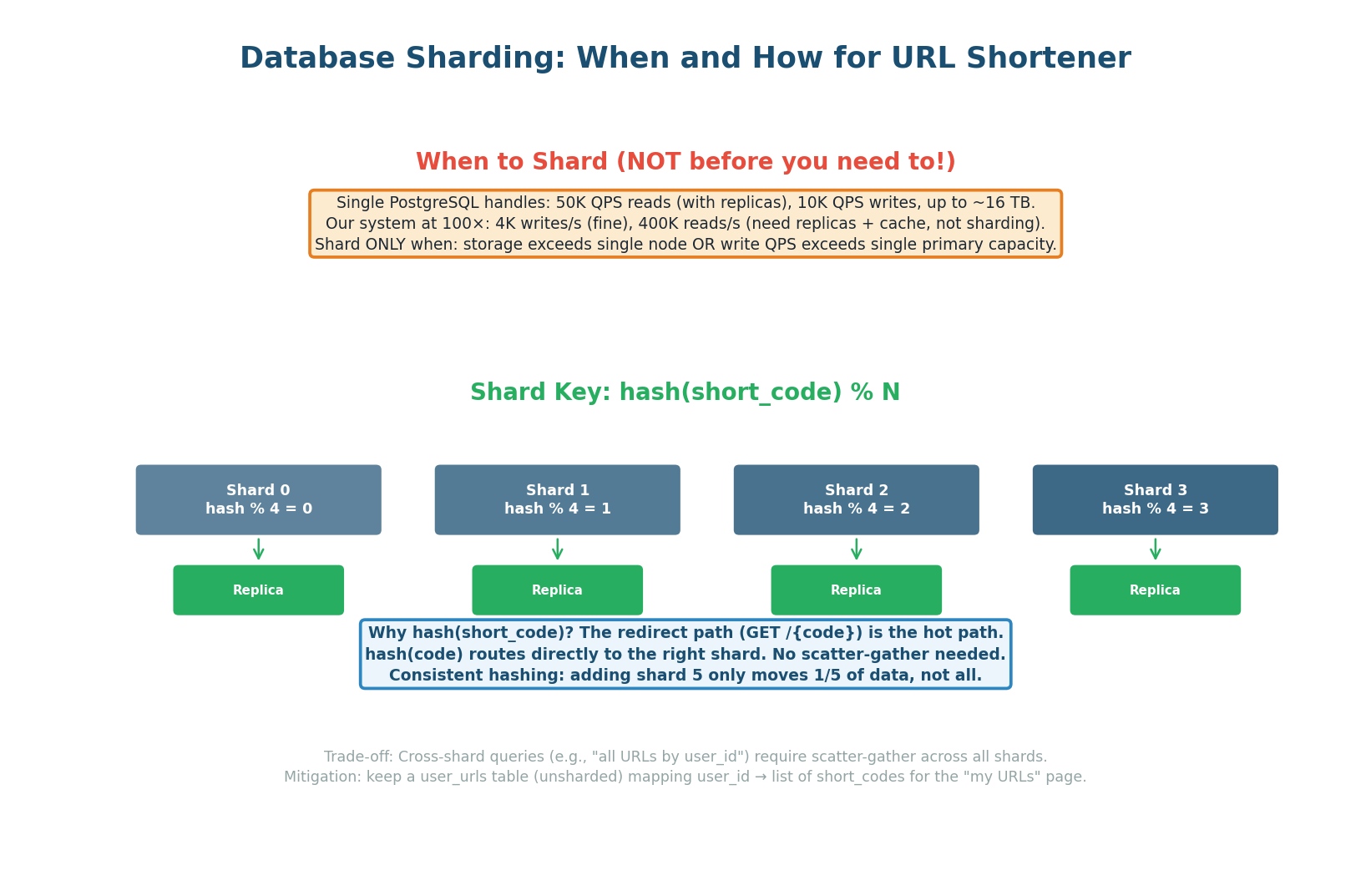
The shard key is hash(short_code) % N. Why short_code and not user_id? Because the redirect path (GET /{code}) is the hot path at 4,000+ reads/sec. With short_code as the shard key, the API server hashes the code, routes directly to the correct shard, and gets the answer in one query. No scatter-gather needed for the most common operation.
| Aspect | Decision | Why |
|---|---|---|
| Shard key | hash(short_code) % N |
Redirect (hot path) routes directly to one shard. O(1) routing. |
| Hashing | Consistent hashing | Adding shard N+1 only moves 1/(N+1) of data, not all. |
| Shard count | Start with 4, grow to 16+ | 4 shards = 75 TB each. 16 shards = 19 TB each (within single-node limits). |
| Replication | Each shard: primary + 2 replicas | Shard-level failover. One shard down does not affect others. |
| Cross-shard queries | Scatter-gather for user's URLs | Mitigate: keep a user_urls index table (unsharded) for "my URLs" page. |
Say in the interview: "I do NOT shard on Day 1. Our estimated 3 TB fits on one PostgreSQL node with 16 TB NVMe SSD. Sharding adds complexity: cross-shard queries, distributed transactions, operational overhead. I shard only when storage exceeds a single node or write QPS exceeds a single primary's capacity. At 100× scale (300 TB), I shard into 4 nodes using consistent hashing on short_code." This shows you scale pragmatically, not prematurely.
Trade-offs & Failure Scenarios
A system design interview is fundamentally about trade-offs. There is no perfect design — only designs optimized for specific requirements. The interviewer wants to hear: "I chose X because of requirement Y. The trade-off is Z. If requirement Y changed, I would choose W instead."
5 Major Decisions with Pros, Cons & Alternatives
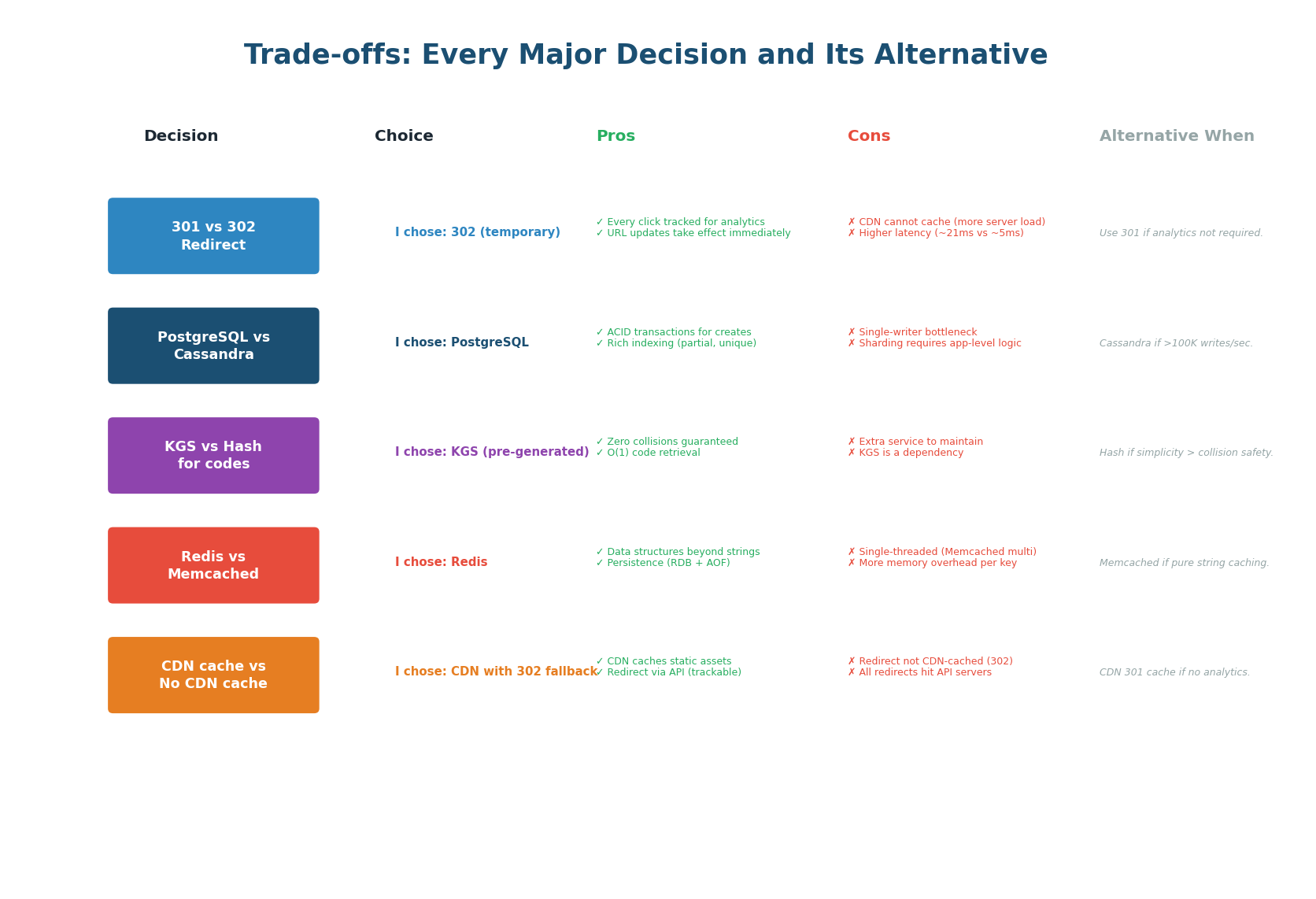
| Decision | Choice Made | Why | Choose Alternative When |
|---|---|---|---|
| 301 vs 302 | 302 (temporary) | Analytics requirement: need per-click tracking | 301 if no analytics needed (faster, CDN-cacheable, 60% traffic saved) |
| PostgreSQL vs Cassandra | PostgreSQL | ACID for creates, rich indexing, 3 TB fits one node | Cassandra if >100K writes/sec or multi-region writes required |
| KGS vs Hash | KGS (pre-gen) | Zero collisions, O(1) retrieval from buffer, scalable | Hash if simplicity is priority and collisions are acceptable |
| Redis vs Memcached | Redis | Data structures, persistence, Sentinel HA | Memcached if pure string caching with multi-threaded performance needed |
| CDN + 302 vs CDN + 301 | CDN for assets, 302 for redirects | Track all clicks; CDN caches static assets only | CDN + 301 if analytics not required (CDN absorbs 60% of redirect traffic) |
"For the redirect status code, I chose 302 (temporary redirect) because our analytics requirement needs per-click tracking. If I used 301 (permanent), the browser and CDN would cache the redirect, and subsequent clicks would never reach our server — invisible to analytics. The trade-off: 302 means every redirect goes through our API server, so I need Redis caching to handle 4,000 reads/sec. If the interviewer later says analytics isn't needed, I'd switch to 301 and let the CDN absorb 60% of traffic for free."
Failure Scenarios & Monitoring

| Failure | Impact | Mitigation | RTO |
|---|---|---|---|
| PostgreSQL primary down | Writes rejected. Reads from cache continue. | Sync replica auto-promotes. RDS handles this automatically. | ~60 seconds |
| Redis cache down | All 4K reads/sec hit DB. Latency 4× (1ms → 5ms). | DB within capacity. Restart Redis, warm organically. | ~5 minutes |
| KGS service down | New URL creation fails. Redirects unaffected. | Each API server buffers 1K codes locally. | ~25s (local buffer) |
| CDN outage | All traffic hits ALB directly. Higher latency for distant users. | Redis + DB absorb. No data loss. Graceful degradation. | 0s (graceful) |
"For monitoring, I track six metrics: p99 redirect latency (target <50ms), Redis hit rate (>95%), DB connection pool utilization (<80%), Kafka consumer lag (<1K), DLQ depth (=0), and KGS buffer level (>100). PagerDuty alerts on breach. A Grafana dashboard shows real-time trends. This gives early warning before any metric reaches critical levels." This 30-second statement elevates your answer from 'Hire' to 'Strong Hire.'
- Database Design:
urlstable with 8 columns. UNIQUE B-tree index onshort_code(2 GB, fits inshared_buffers). Partial indexes onexpires_atanduser_id. KGS pre-generates Base62 codes → API server local buffer → zero collisions at O(1).click_countupdated async via Kafka (never in the redirect hot path). - Caching Strategy: Three layers: CDN (60% hit, <5ms), Redis (35% hit, <1ms), PostgreSQL (5% hit, ~5ms). Total 95%+ hit rate. Redis: 512 MB, allkeys-lru, 1h TTL, Sentinel for HA. Cache 404s for 5 min to prevent DB hammering. Key pattern:
url:{short_code}= long_url. - Scaling Plan: Stage 1 (Day 1): 1 PG primary + 2 replicas, 1 Redis, 3 API servers. Stage 2 (10×): 4 replicas, 5 GB Redis, 10 API servers. Stage 3 (100×): PG sharded by
hash(short_code), Redis Cluster, 50+ API servers. Trigger: shard when storage exceeds single-node capacity. - Trade-offs: 302 for analytics (vs 301 for CDN caching). PostgreSQL for ACID (vs Cassandra for massive writes). KGS for zero collisions (vs hash for simplicity). Redis for data structures + persistence (vs Memcached for pure speed). Every decision justified by requirements.
- Failures & Monitoring: DB failover 60s (sync replica promotes). Redis down = 4× latency (DB absorbs). KGS down = 25s buffer. CDN down = graceful degradation. Six metrics monitored: p99 latency, cache hit rate, DB pool, Kafka lag, DLQ depth, KGS buffer.
Want to Land at Google, Microsoft or Apple?
Watch Pranjal Jain's free 30-min training — the exact GROW Strategy that helped 1,572+ engineers go from TCS/Infosys to top product companies with a 3–5X salary hike.